【从零开始的机器学习之旅】02-Deeplearning-general_guidance
1.Ups and downs of Deep Learning

2. Three Step for Deep Learning
Step1:Neural Network
Neural Network: 点击查看更多
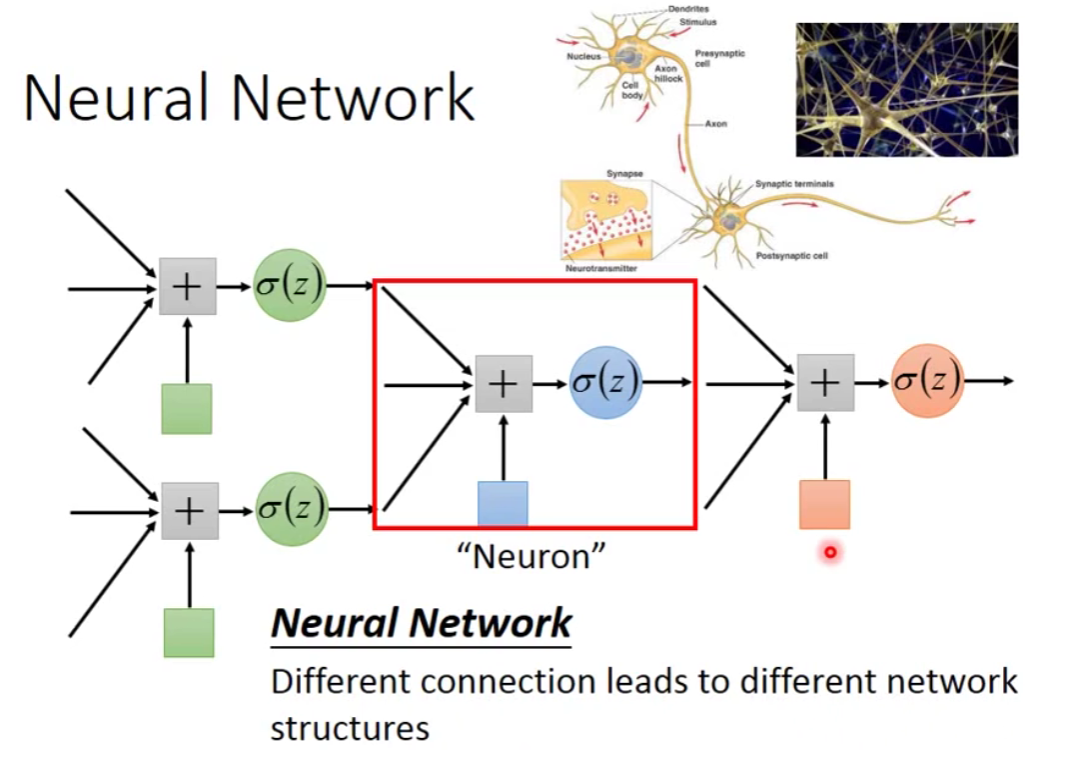
Network parameter
那么多的neuron我们应该怎么把它接起来呢?
有很多种方法。究竟怎么连接其实是你手动设定的。
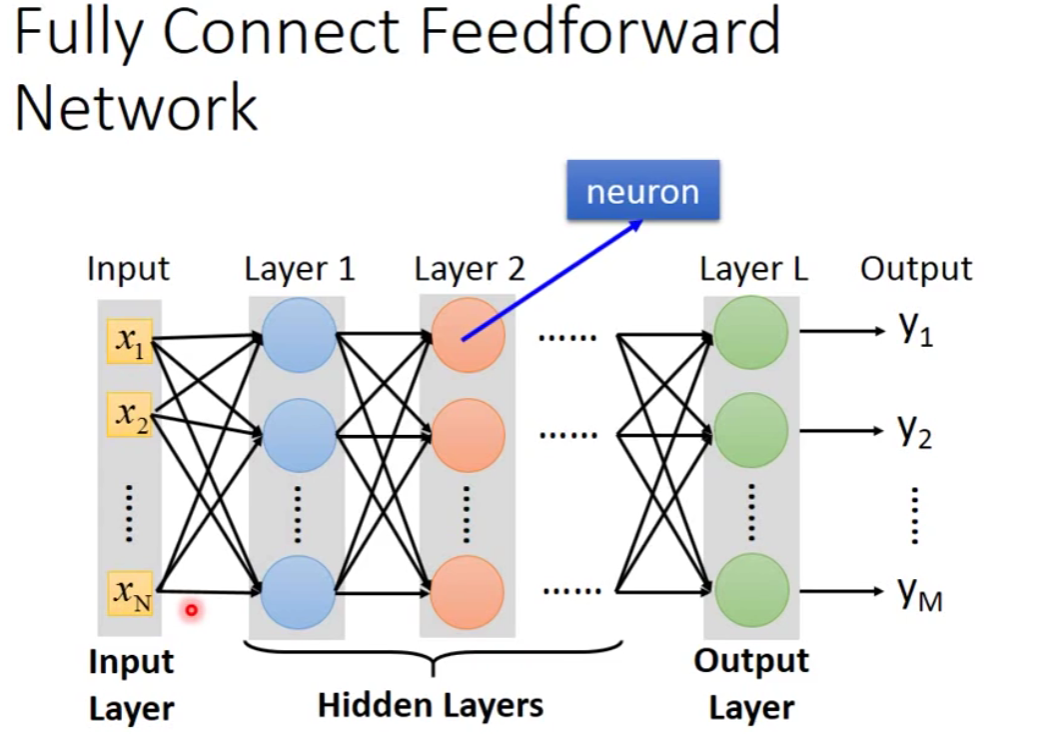
Fully Connect Feedforward Network
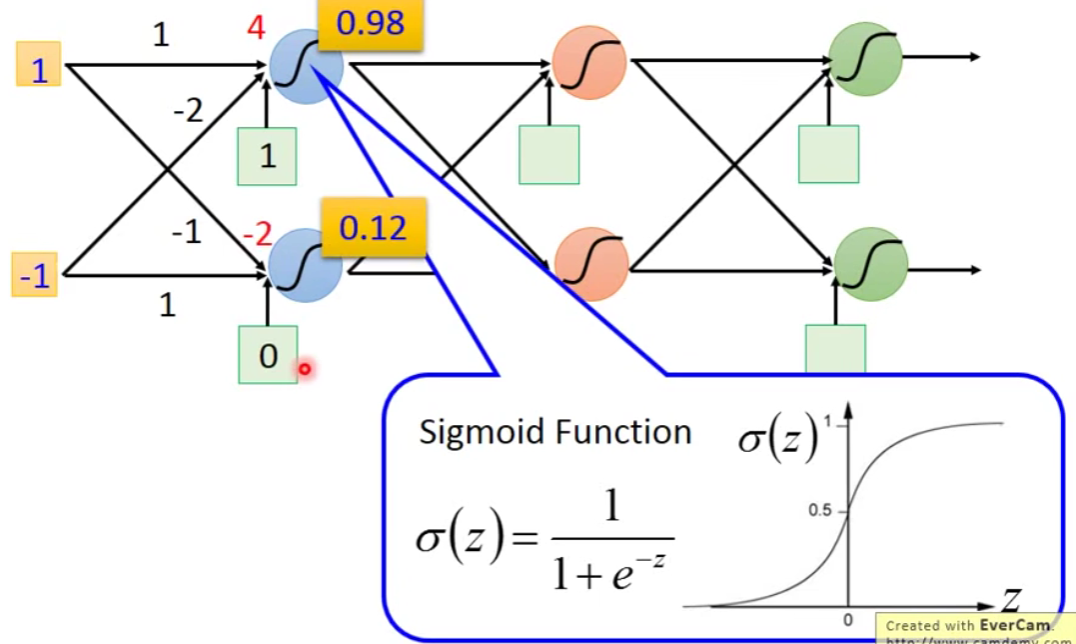
箭头上的表示weight,红色的数字代表bias。我们让
假设这个structural里面的所有的neuron它的weight和bias我们都是知道的,我们就可以反复进行上面的运算。
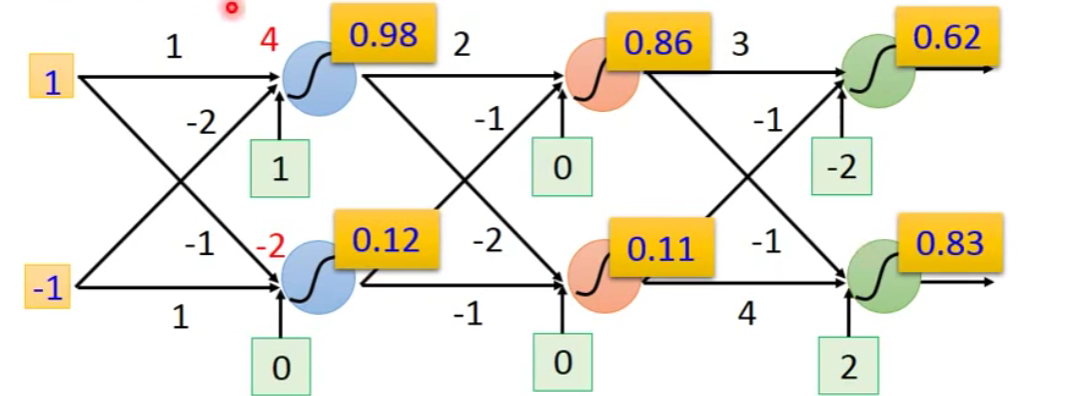
当我们输入1和-1之后呢,我们得到0.62和0.83。
尝试改变我们的输入:
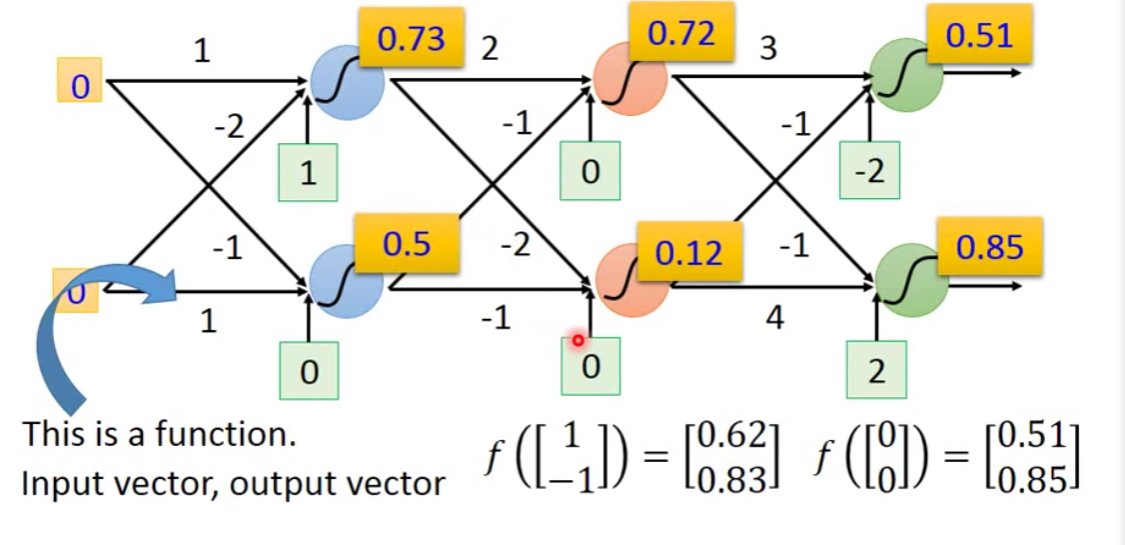
输入0和0之后呢,我们会得到0.51和0.85。
那么对于一个neural network,我们可以把它看作一个function。
那么如果今天我不知道每一个neuron的weight和bias的话,但是有了连接的方法,其实就相当于我们是定义了一个function set。
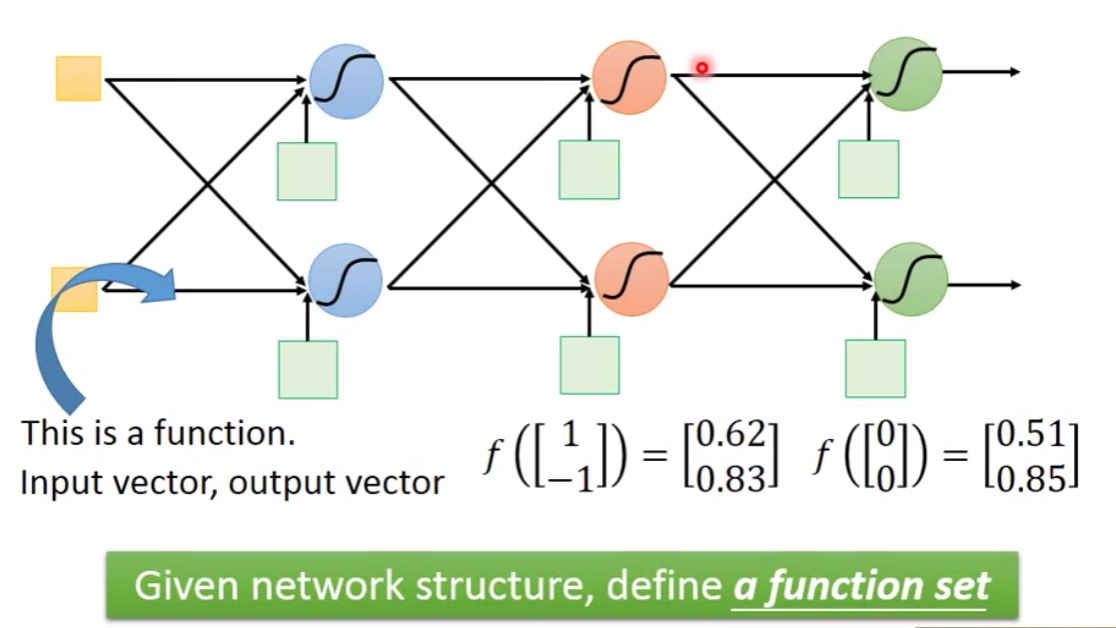
In general:
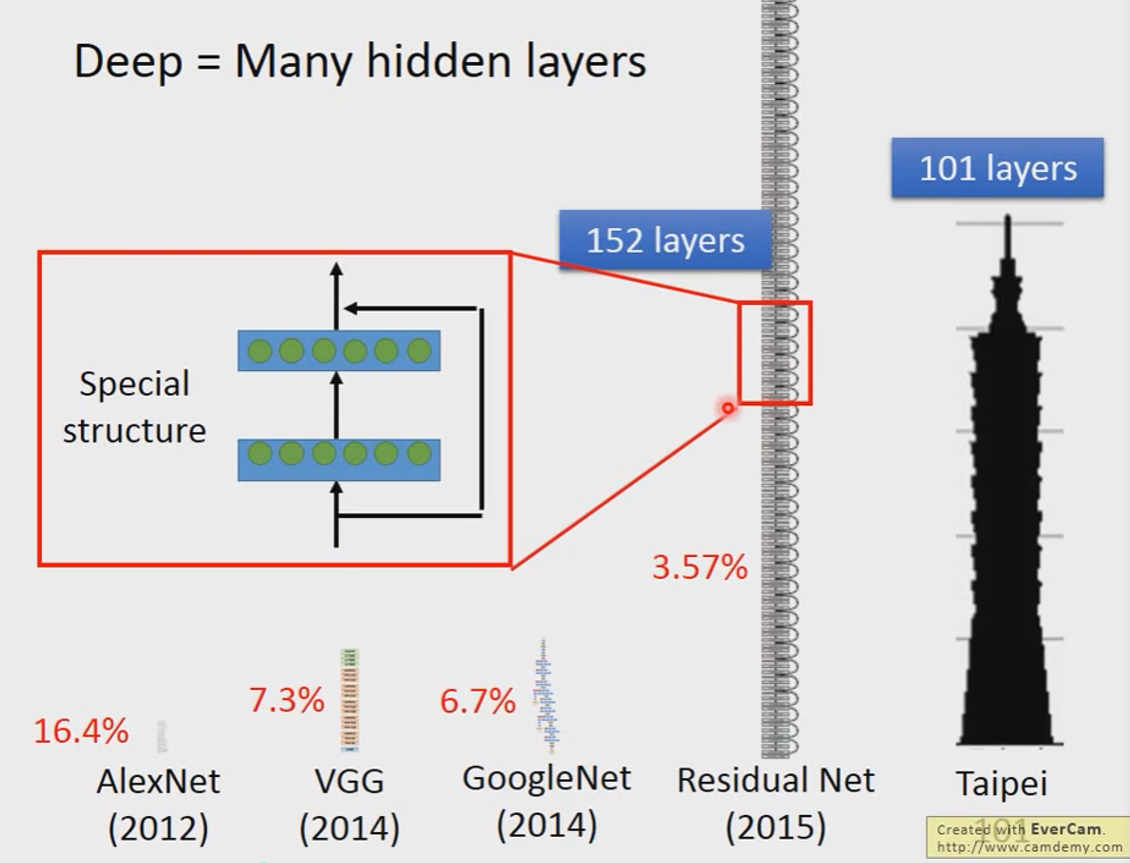
Deep = Many hidden layers
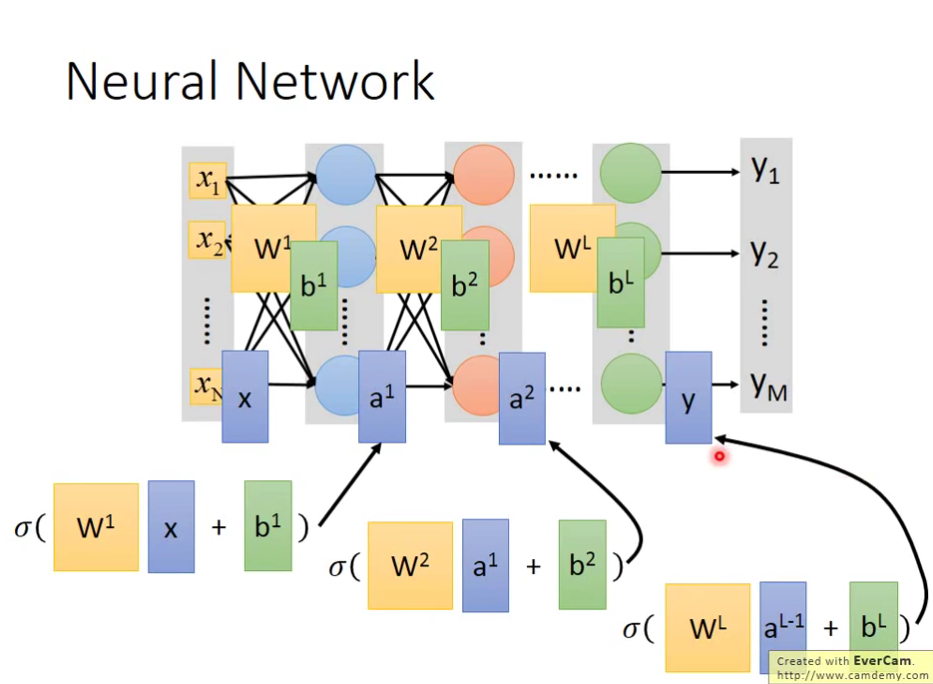
Network 如何运作呢?
我们通常会用Matrix Operation的方式进行。
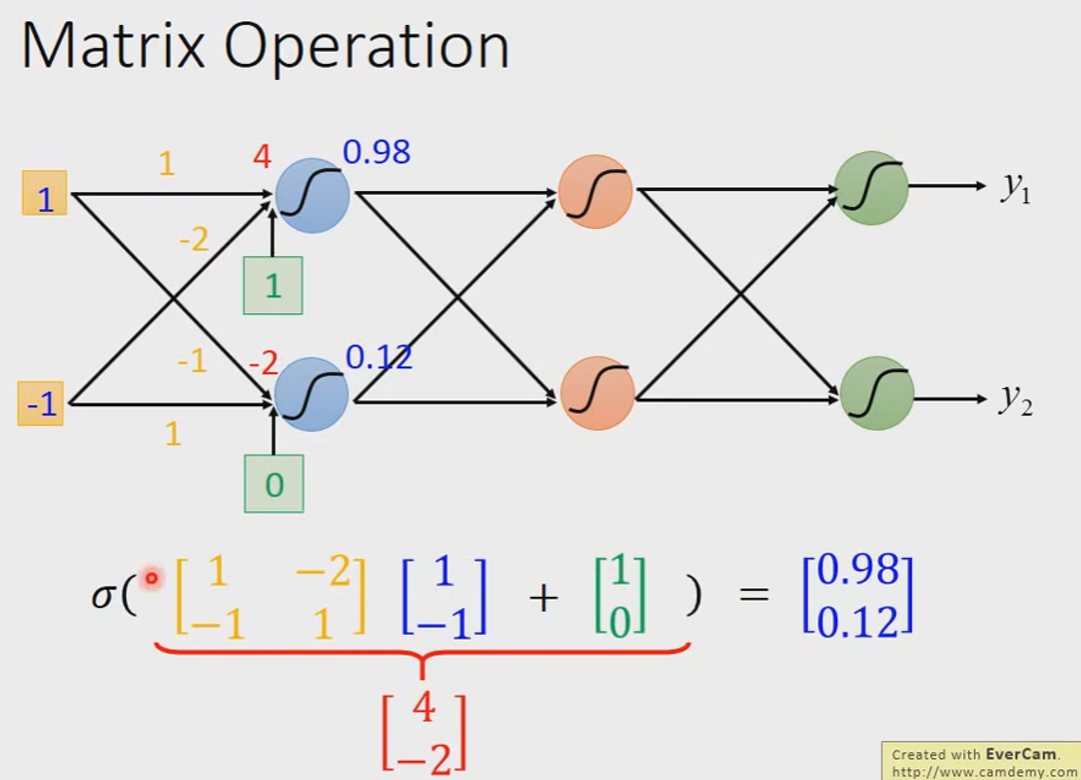
In general:

写成矩阵形式的好处是什么呢?你可以用GPU加速。
关于Output Layer
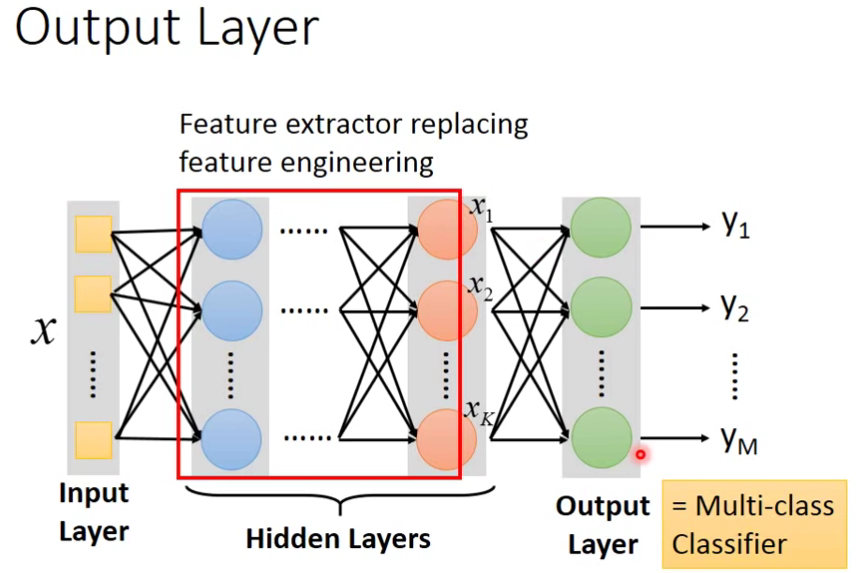
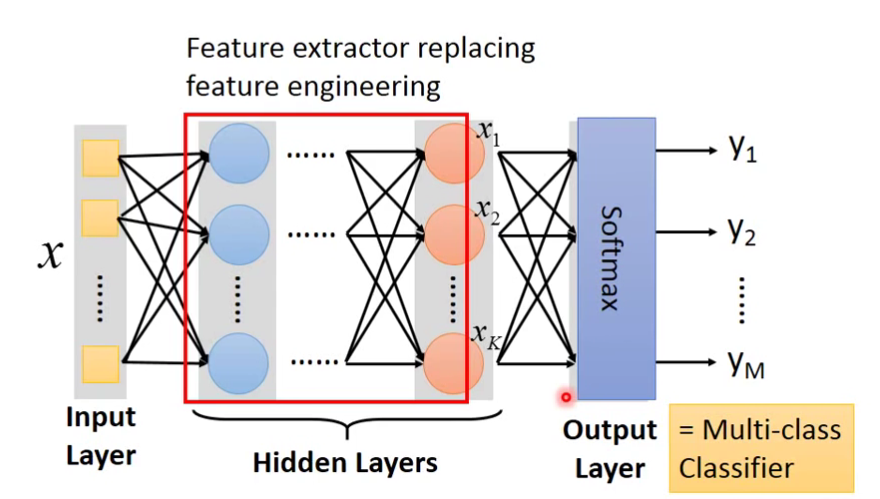
Example Application
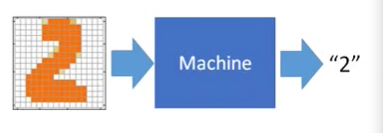
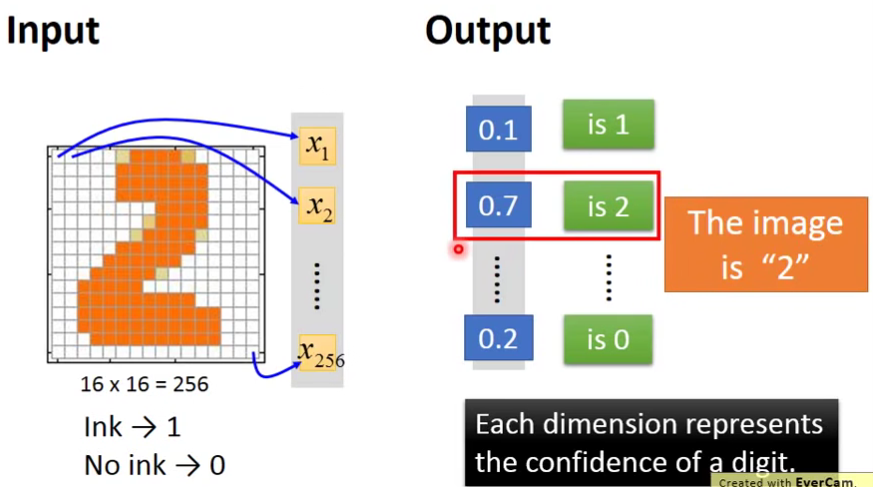
输入是256个维度的特征,输出是代表是某一个数字的概率。
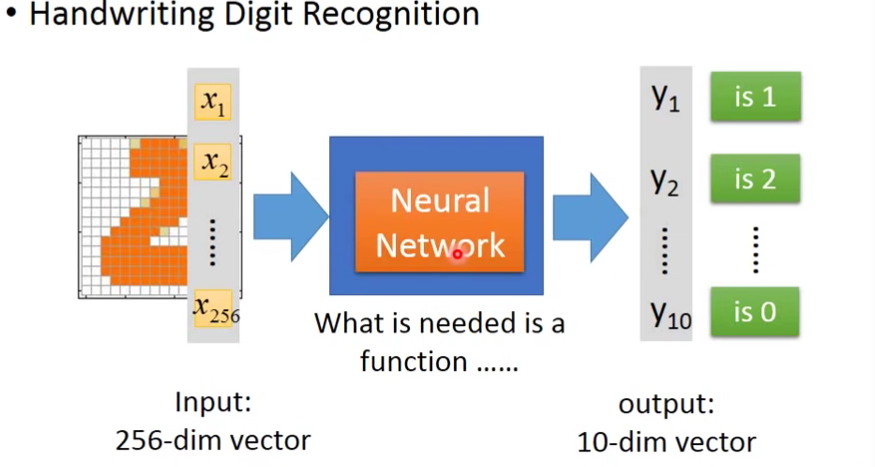
那么Neural Network要如何设计呢?比如以手写数字判断的例子为例。如果当前这个Neural固定是输入256维,输出是10维的,那么它就可以用了做预测手写数字的Network。
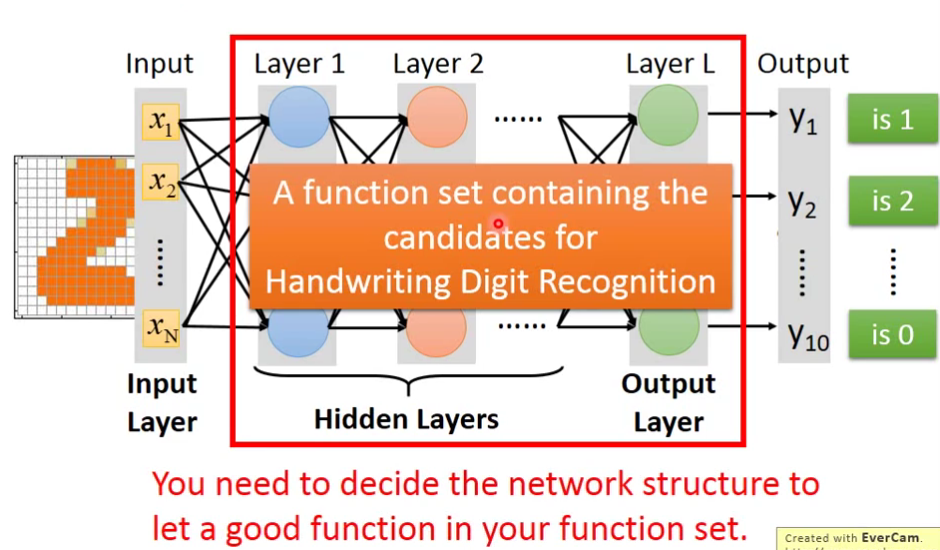
也就是说,目前的限制只有输入和输出的维度,而我们中间的维度是没有限制的,层数也是没有限制的。我们需要自己去设计它,我们需要去决定function set长什么样子。
Q&A
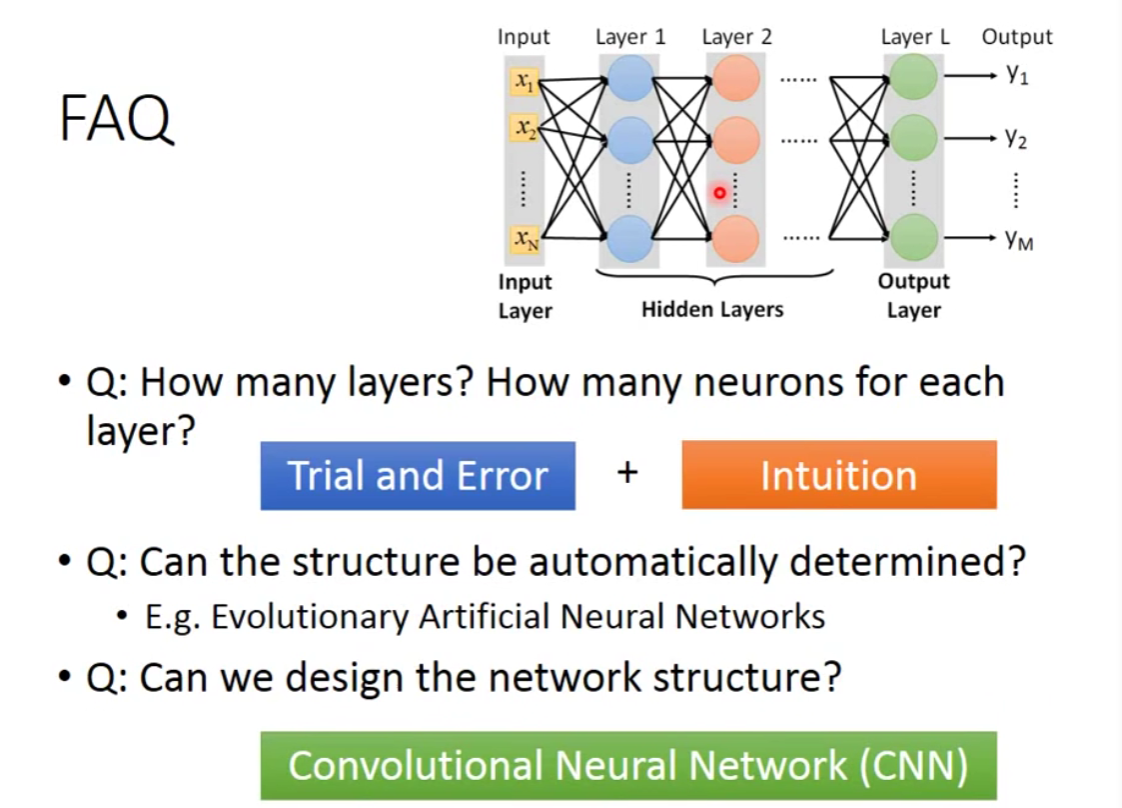
Step2:goodness of function
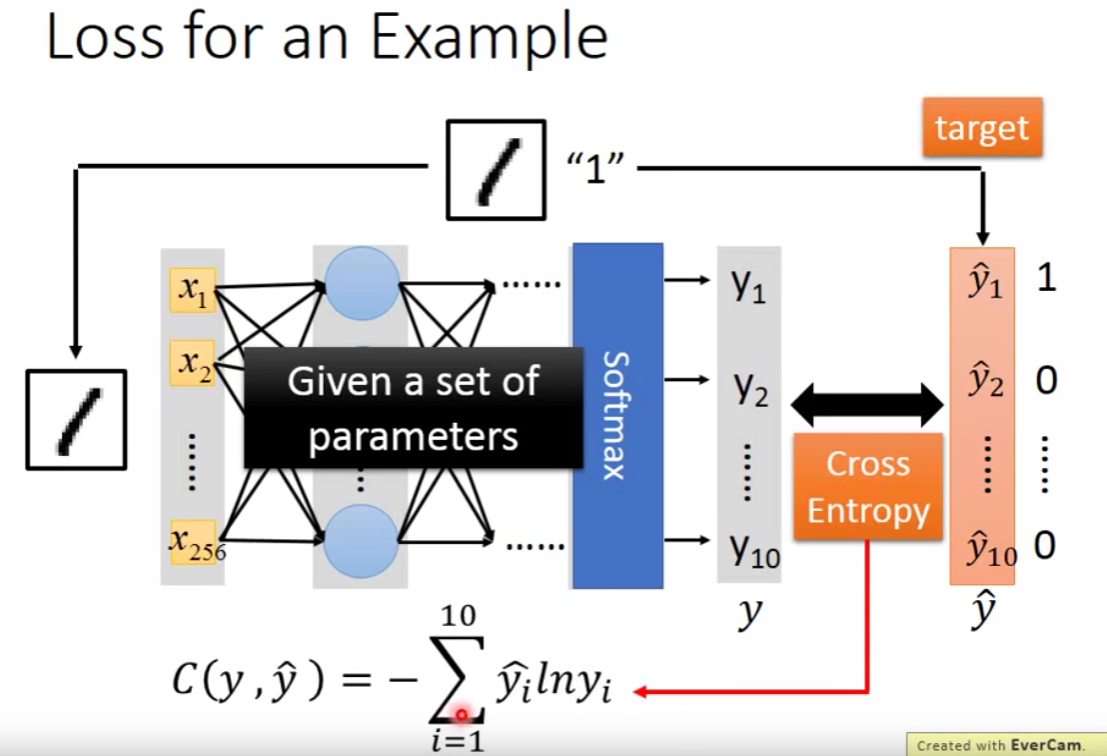
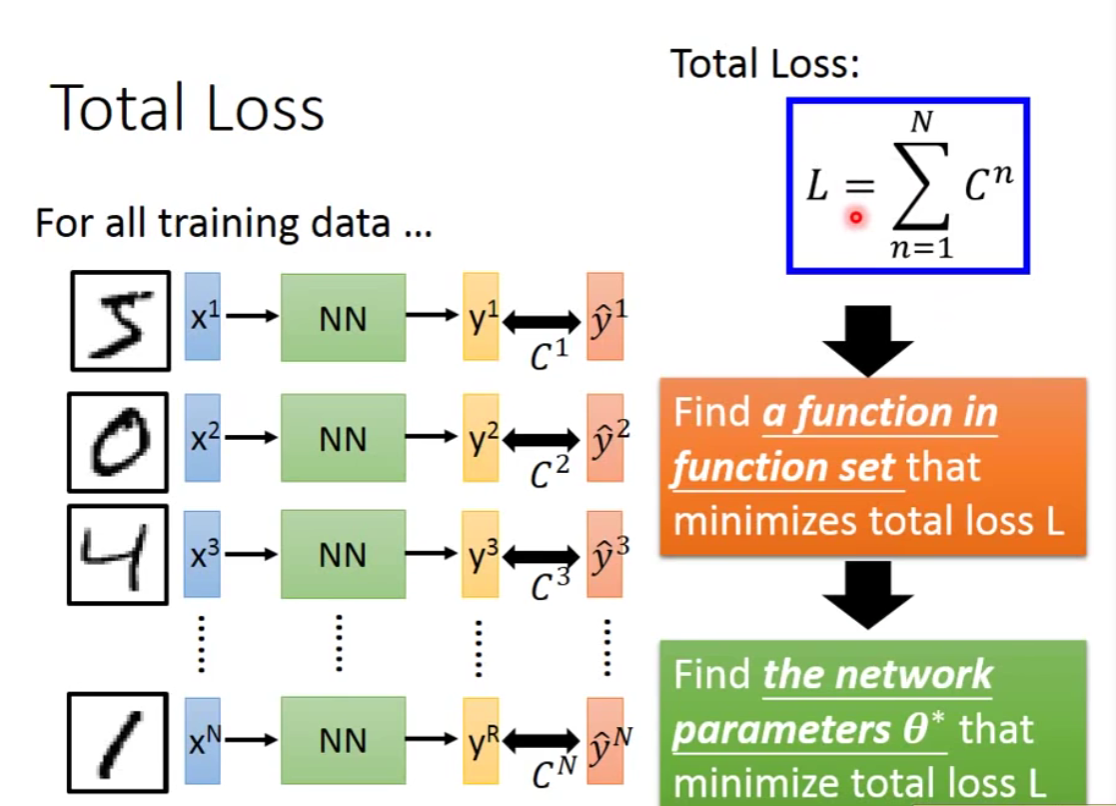
step3:pick the best function
那么我们如何去找这个minimizes total loss L呢?
—— Gradient Descent
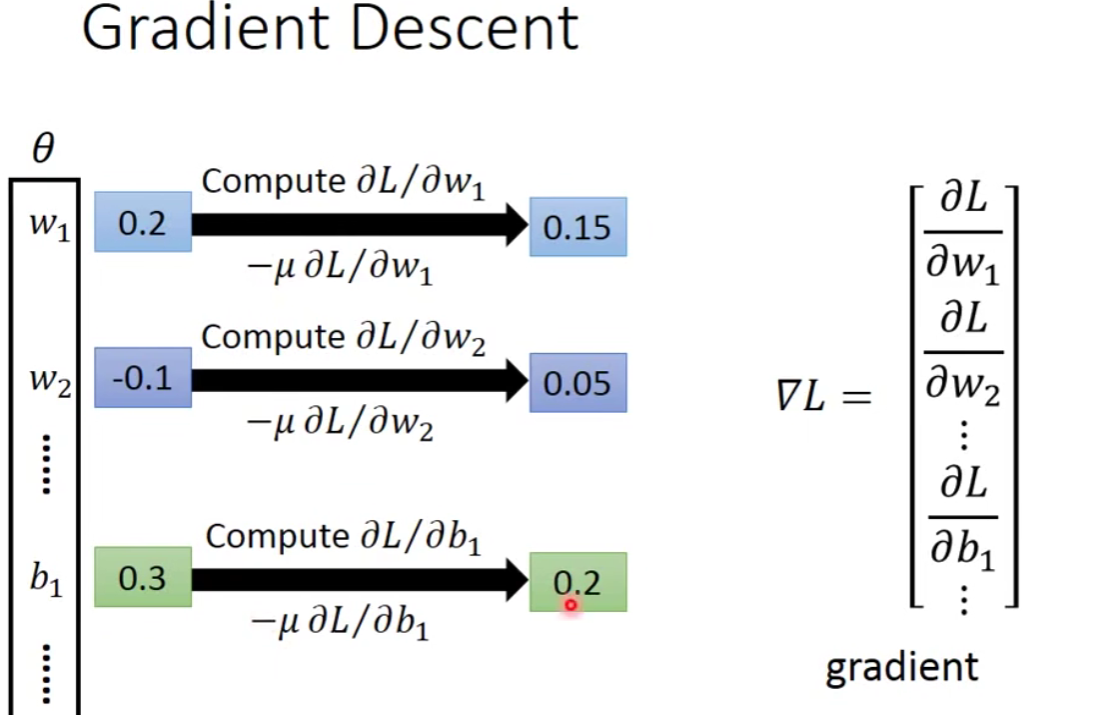


关于如何计算这个微分?
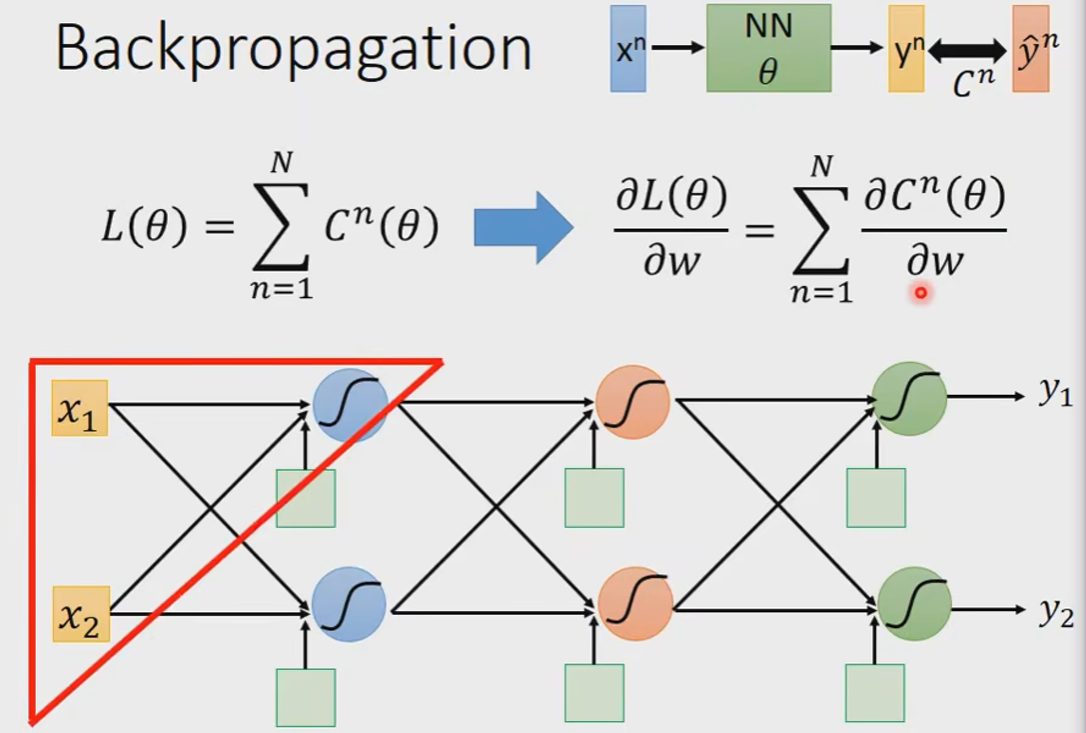
Backpropagation(反向传播)
- Backpropagation: an efficient way to compute
in neural network.

Backpropagation: 点击查看更多
为什么需要Backpropagation?

参数量实在是太多啦。
——To compute the gradients efficiently,we use backpropagation.
前置知识:Chain Rule(链式法则)
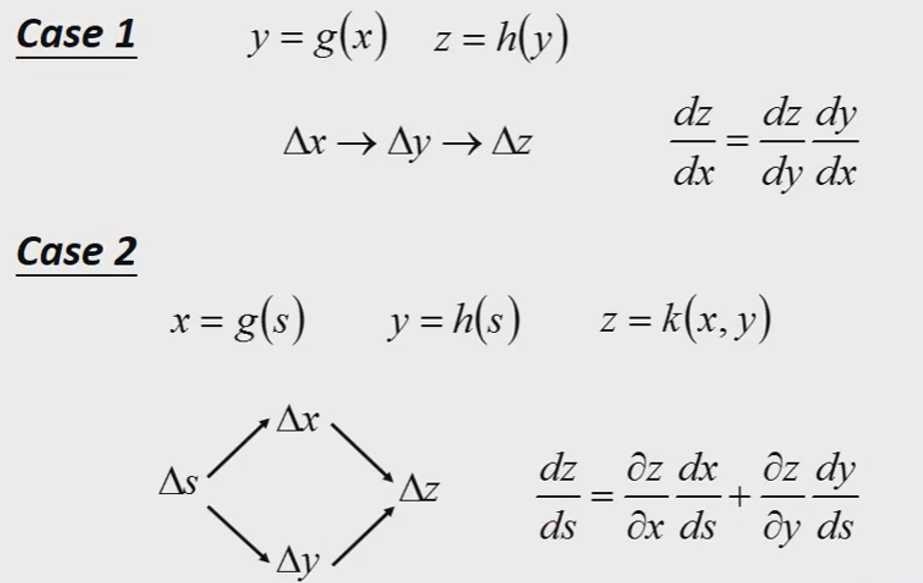
我们先考虑简单的,三角形区域的一个neuron。
我们以

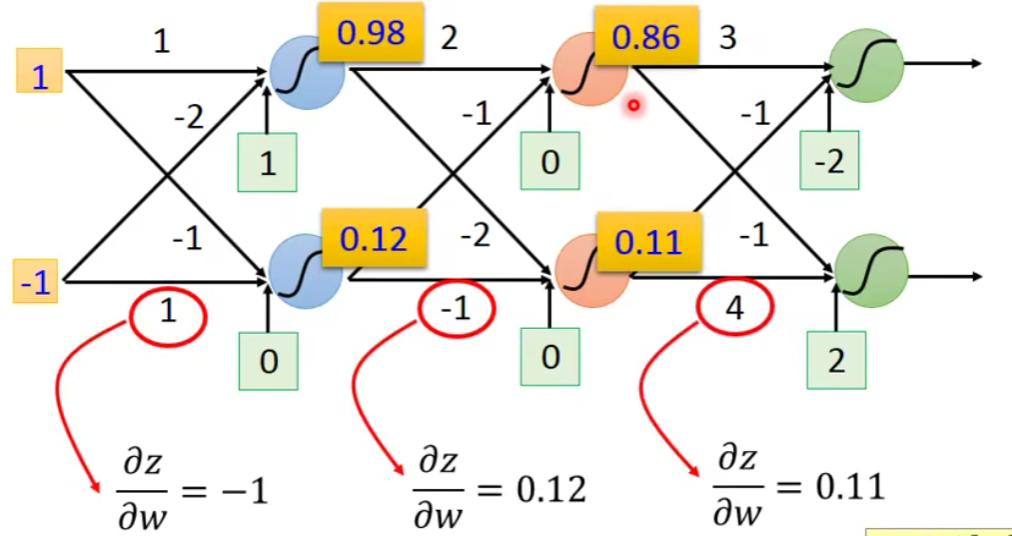
我们发现一个规律就是我们要求对谁的偏导,其实看它前面的系数就好了,也就是这个partial的input。
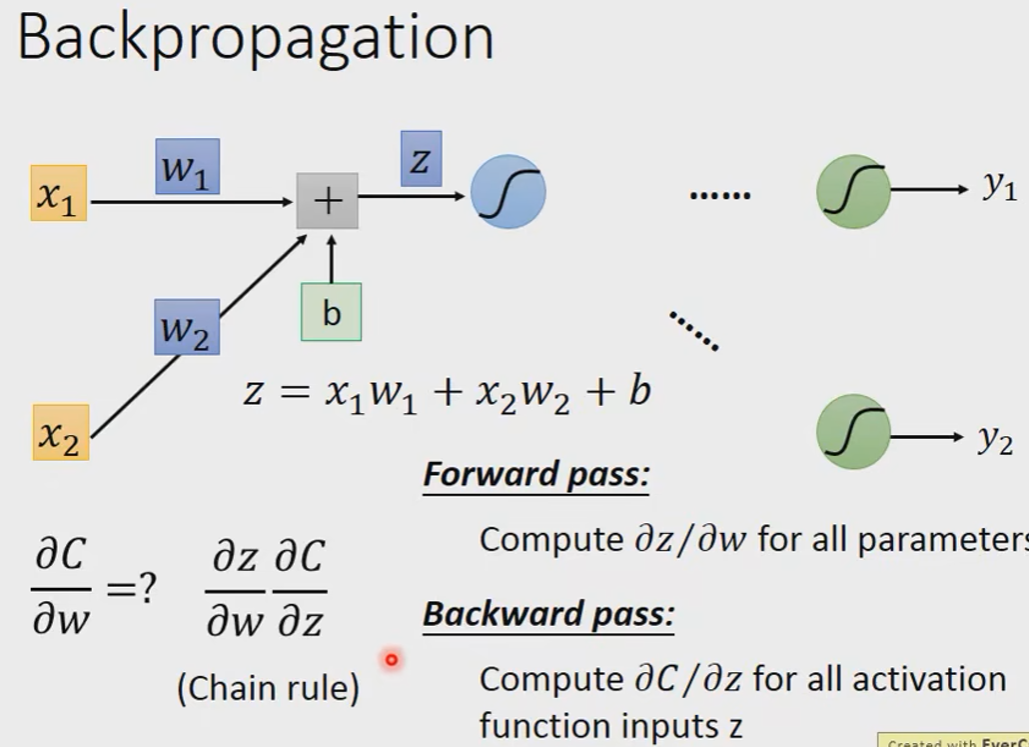
Forward pass
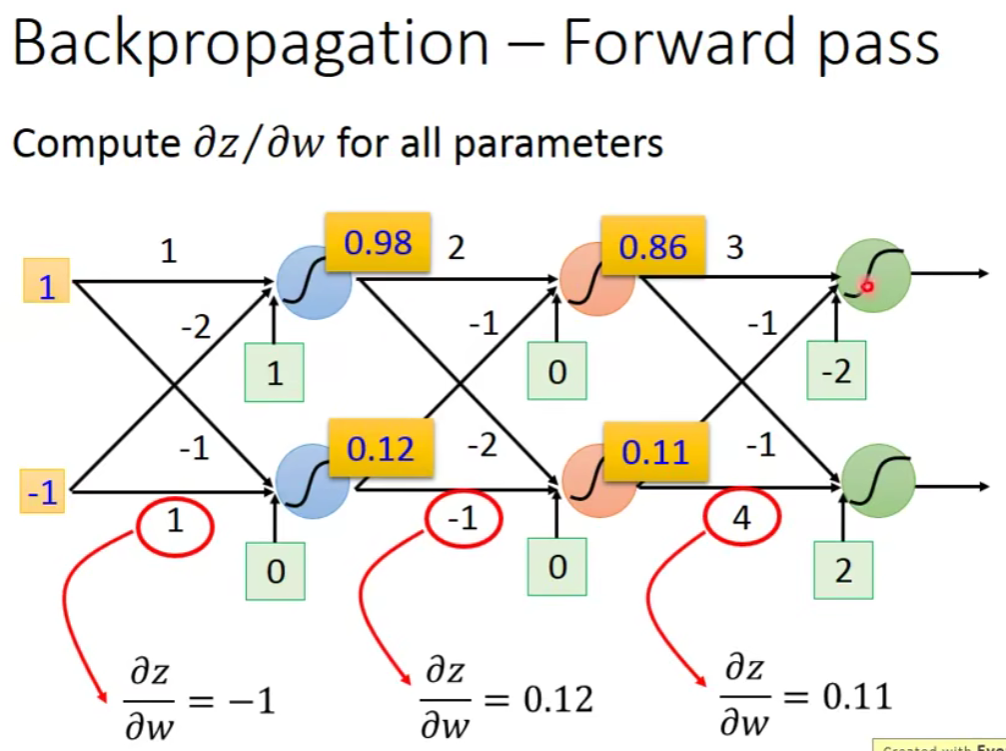
Backward pass
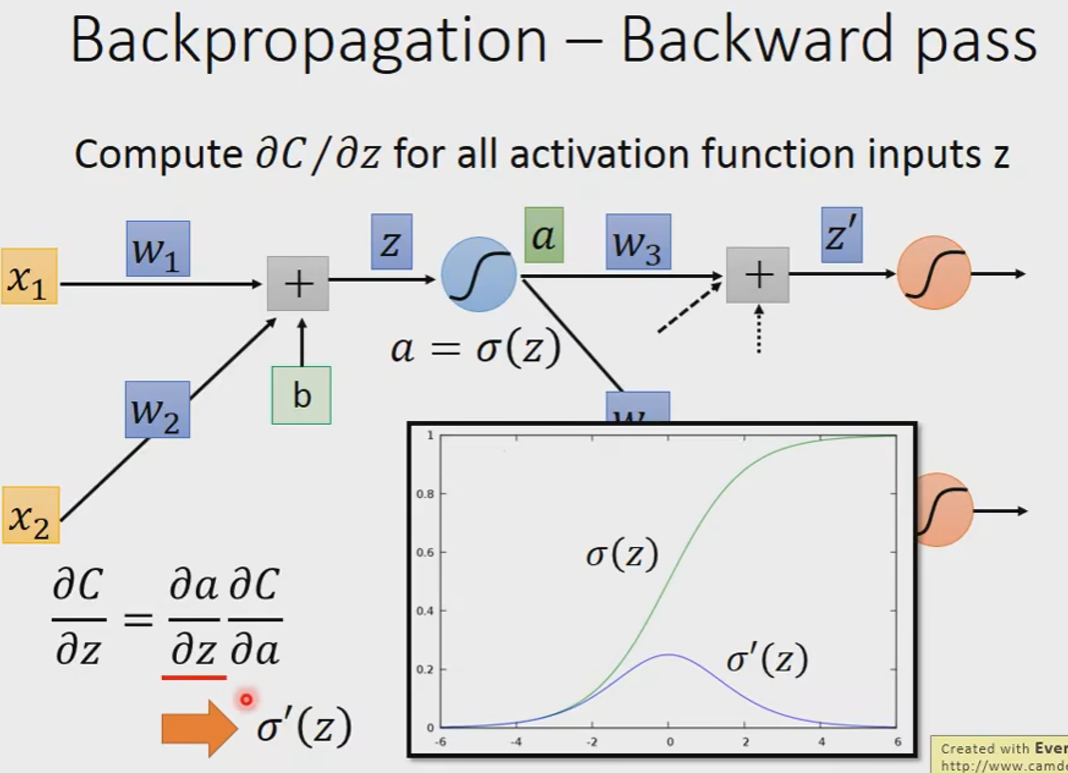
我们先假设我们知道
我们换一个角度去看这件事情:
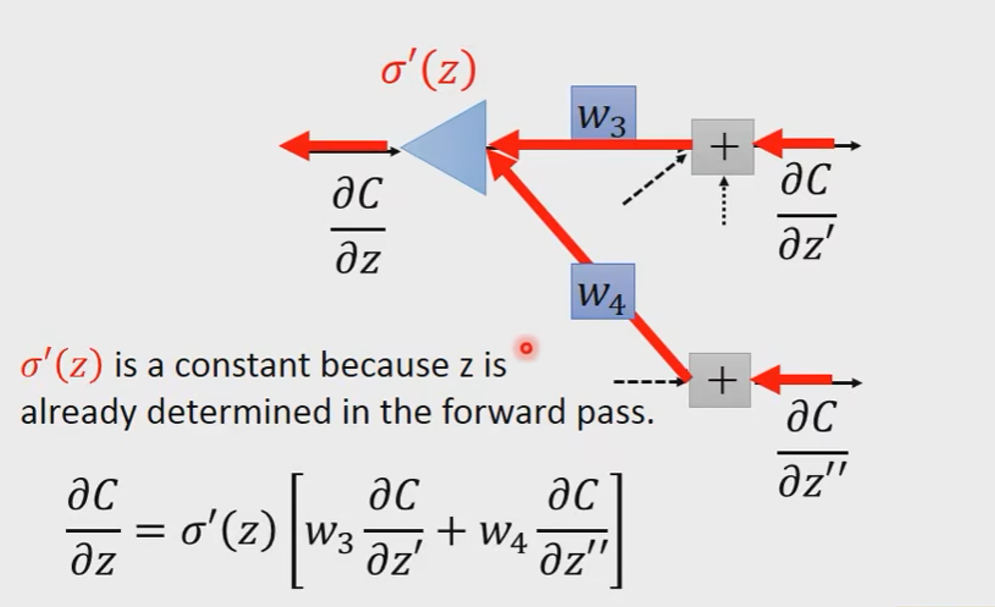
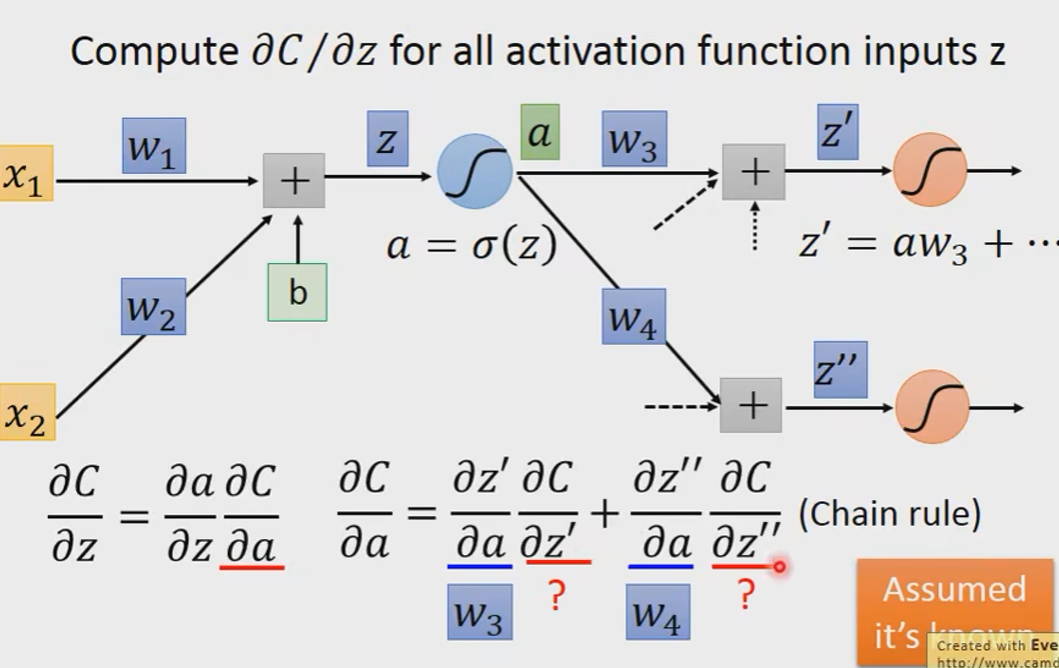
z是在算forward pass的时候就已经被决定好了的,它是一个常数。
那么最后的问题就是怎么算
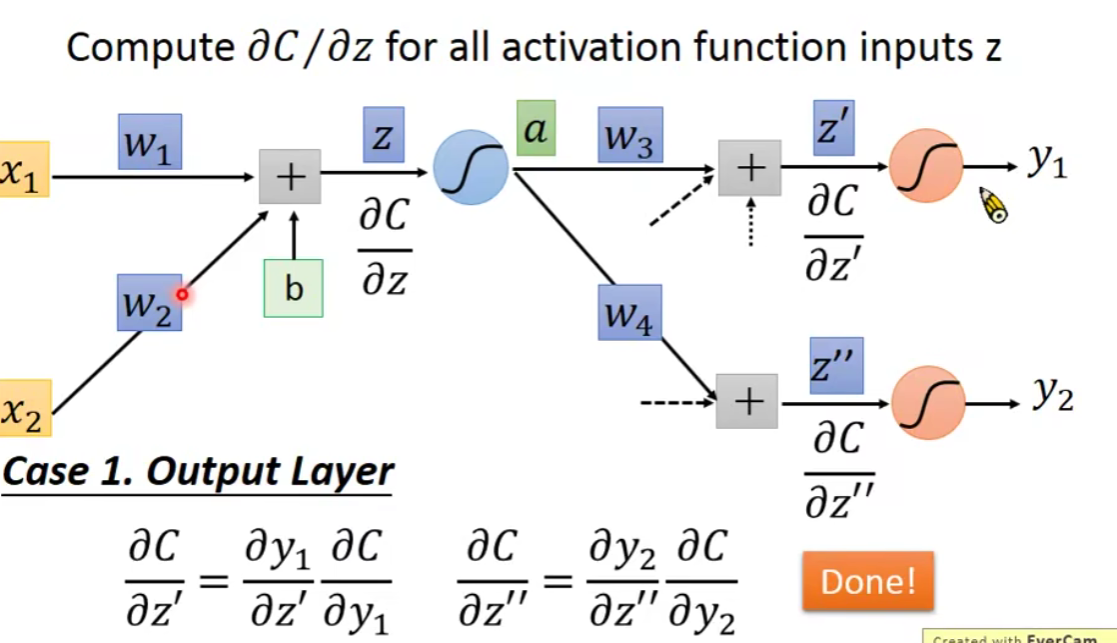
考虑两个情况:
Case1:Output Layer
Case2:Not Output Layer
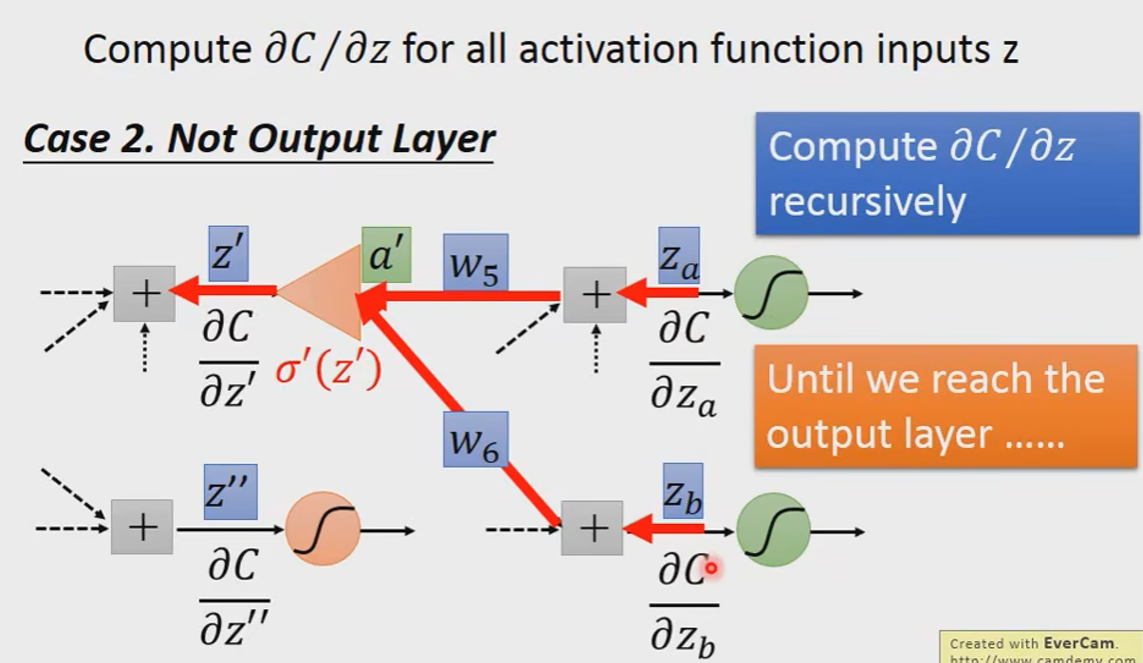
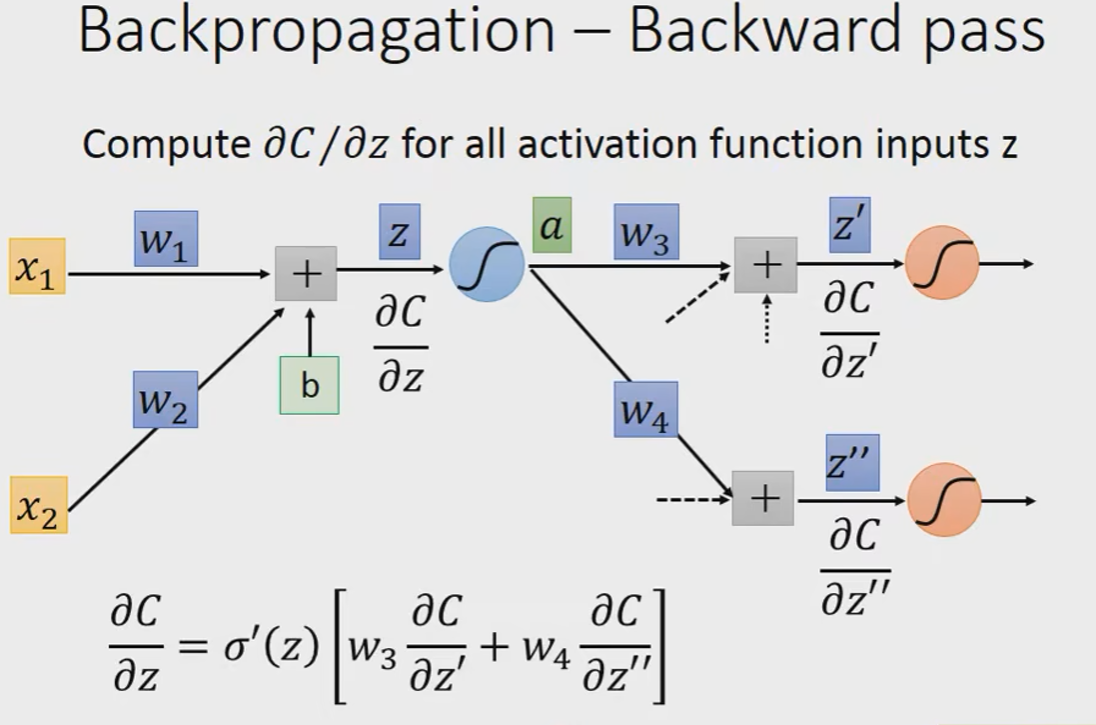
In general:
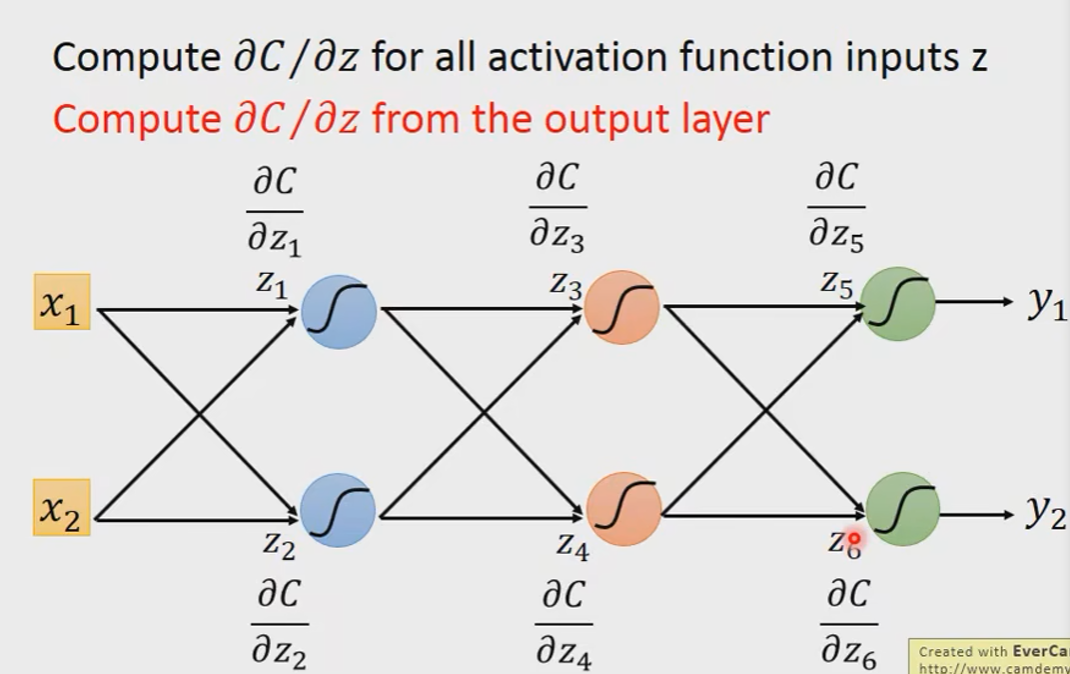
即:
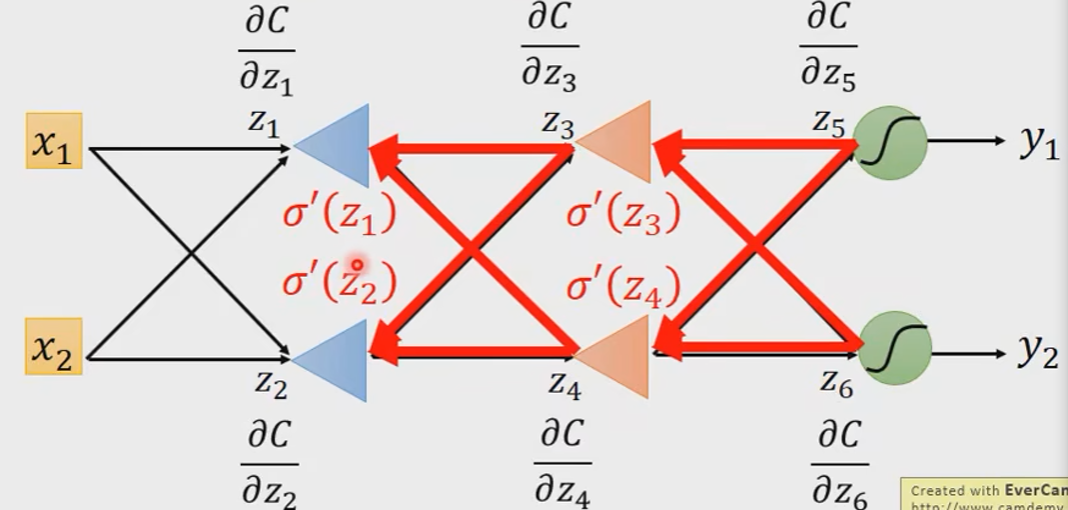
就好像我们建了一个反向的neural network
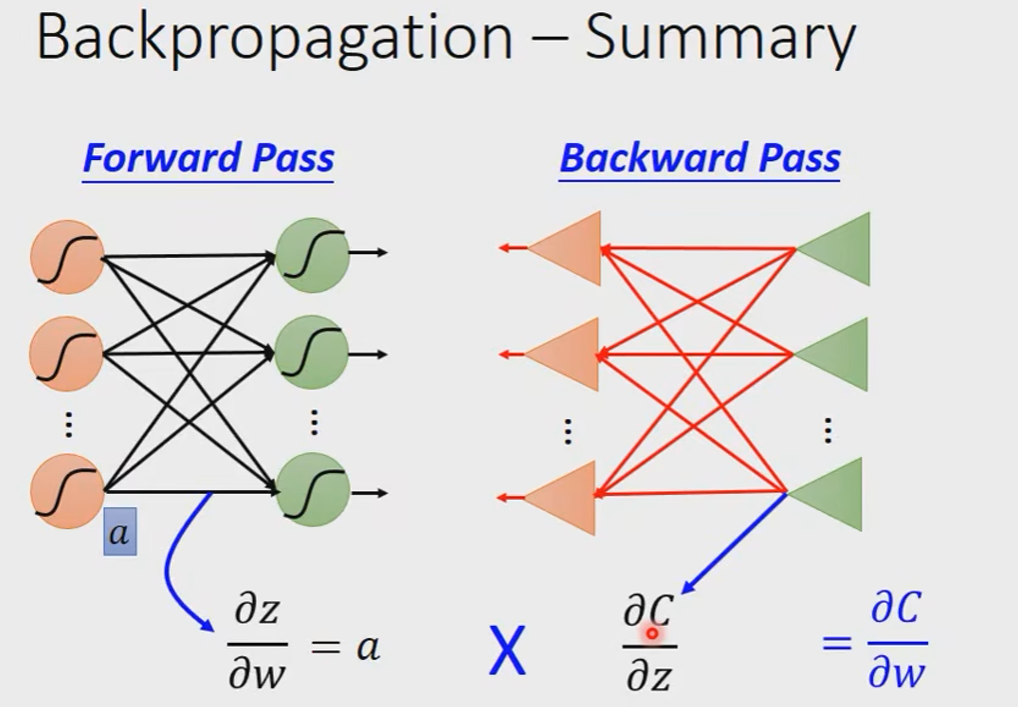
Summary
3. Deeper is Better?
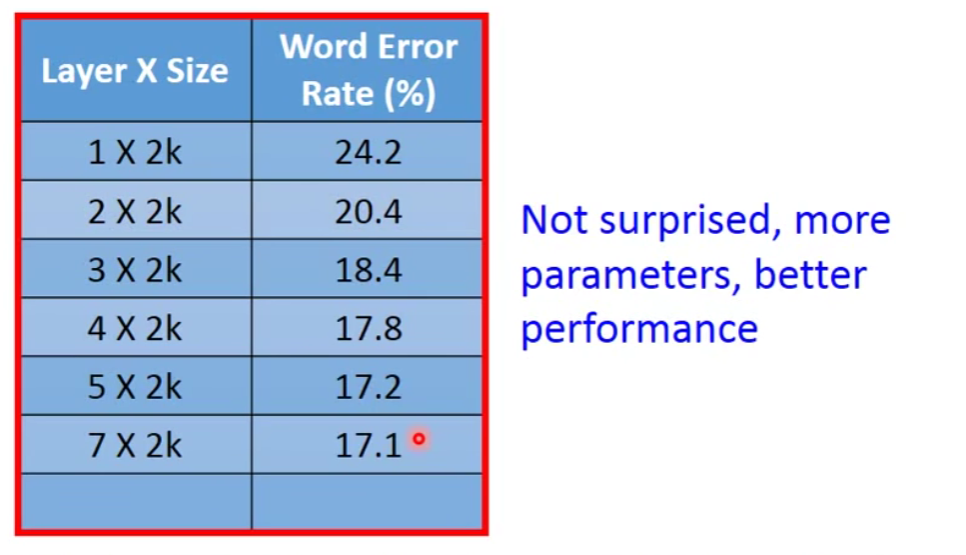
让我们来看一个有趣的理论

这个理论就是说,任意连续的function,假设输入是N维,输出是M维,它都可以用一个hidden layer来表示(只有足够多)。
那么问题就来了,既然一个hidden layer就可以表示成任何函数,那么我们为什么还要做Deep呢?
Why “Deep” neural network not “Fat” neural network?
在后续的学习中会解答这个问题…
- Title: 【从零开始的机器学习之旅】02-Deeplearning-general_guidance
- Author: Nannan
- Created at : 2024-06-25 21:55:12
- Updated at : 2024-09-29 23:20:52
- Link: https://redefine.ohevan.com/2024/06/25/02-Deeplearning-general_guidance/
- License: This work is licensed under CC BY-NC-SA 4.0.