【从零开始的机器学习之旅】07-Recurrent Neural Network(RNN) PartⅠ
从零开始的机器学习之旅
1.Example Application
先以一个智能机器人的例子开始。
理解一段文字的一种方法是标记那些对句子有意义的单词或记号。在自然语言处理领域,这个问题被称为槽填充(Slot Filling)。
所以此时机器人要找出input句子的有用的信息(destination,time of arrival),然后输出要回答的答案。
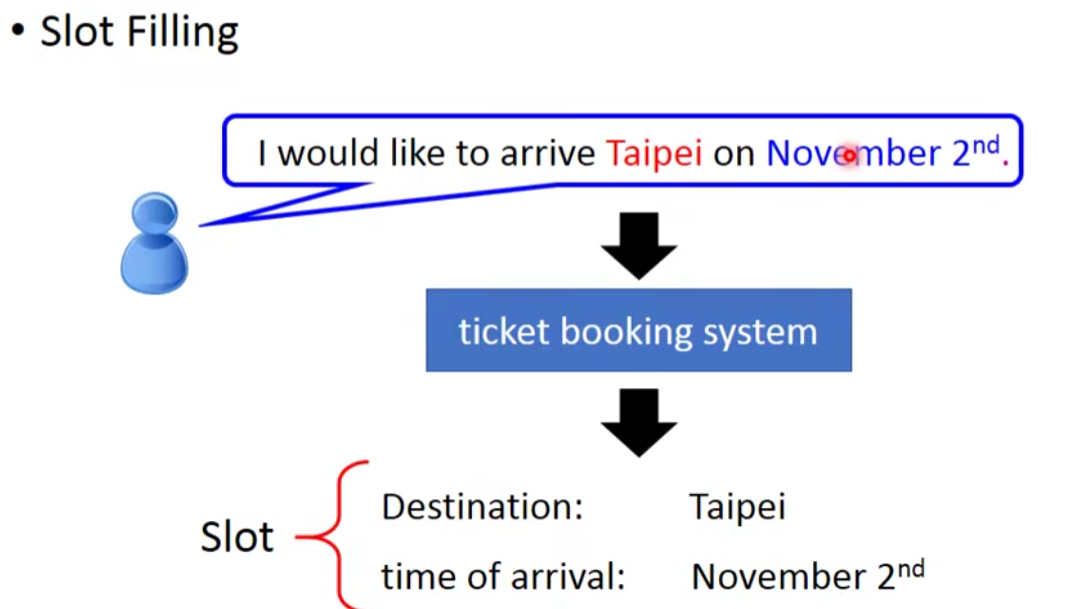
那么这个问题要怎么解决呢?
Solving slot filling by Feedforward network?
input::a word(Each word is represented as a vector)
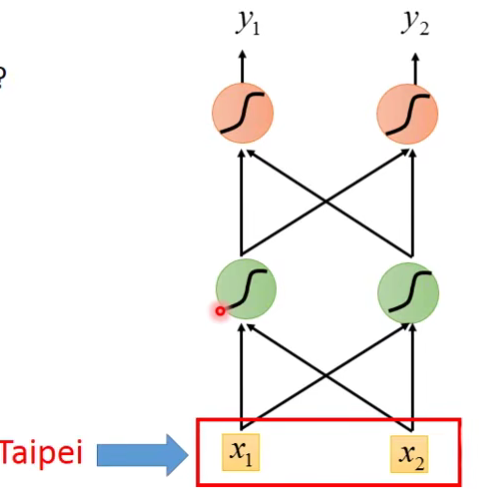
怎么把词语转成vector呢?

这个方法很简单,将物品在对应的列上置1 。
缺点:如果出现lexicon没有记录的物品,没办法在所属的列上置1 。
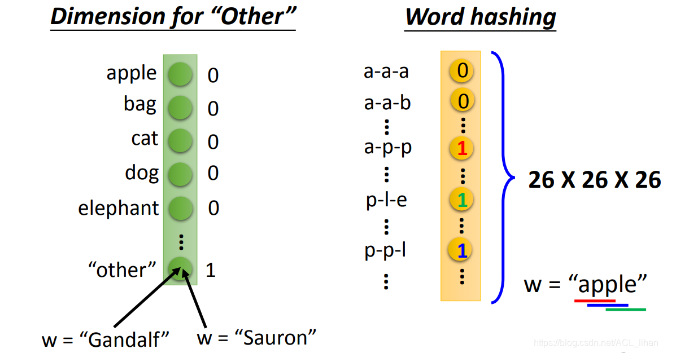
- Dimension for “Other” : 把没记录过的物品归到 other 类里。
- Word hashing : 用词汇的字母的n-gram来表示这个vector
output:Probability distribution that the input word belonging to the slots。(这个输出是一个分布,这个分布是输入的词汇(比如Taipei)属于哪个slot(destination,time of arrival)的几率。)
这样看起来好像很合理,但是其实是有问题的,比如说:
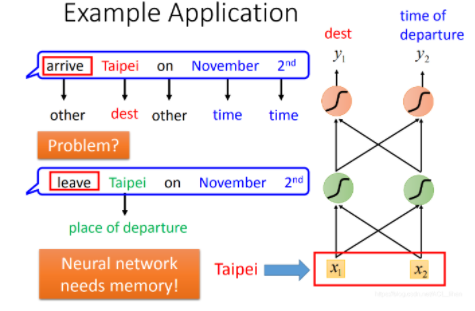
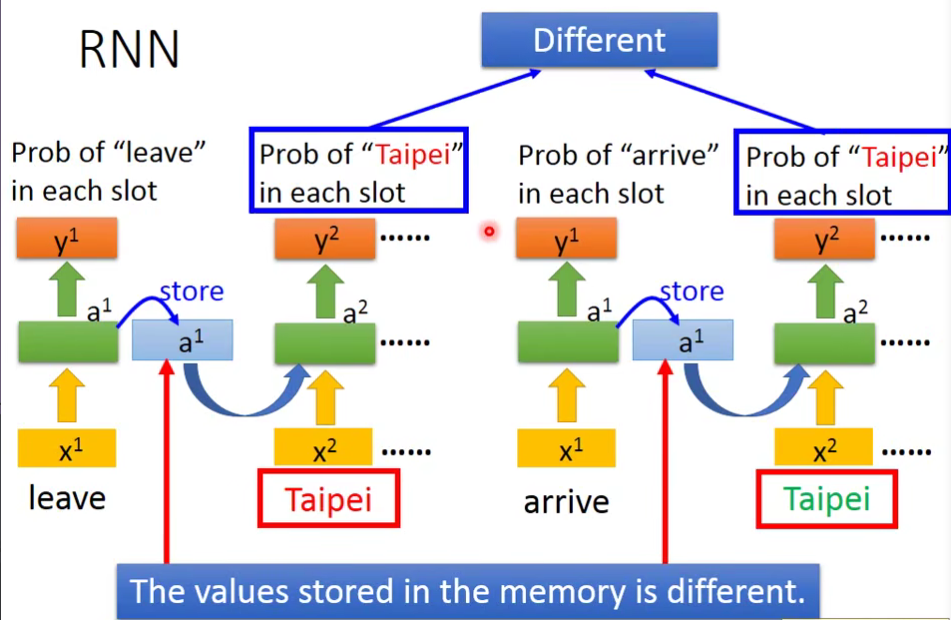
如果network的input是一样的,那output应该也是一样的,但现在面临个问题:
现在有两个句子:
- 11月2号到达台北(台北是目的地)
- 11月2号离开台北(台北是出发地)
对于刚才的network来说,input只有台北,它要么就一直认定台北是目的地,要么就一直认定台北市出发地。
所以,我们就希望这个network是有记忆力的,能记住联系台北之前的词汇,来判断台北市目的地还是出发地。
这种有记忆力的network就是循环神经网络(Recurrent Neural Network,RNN)。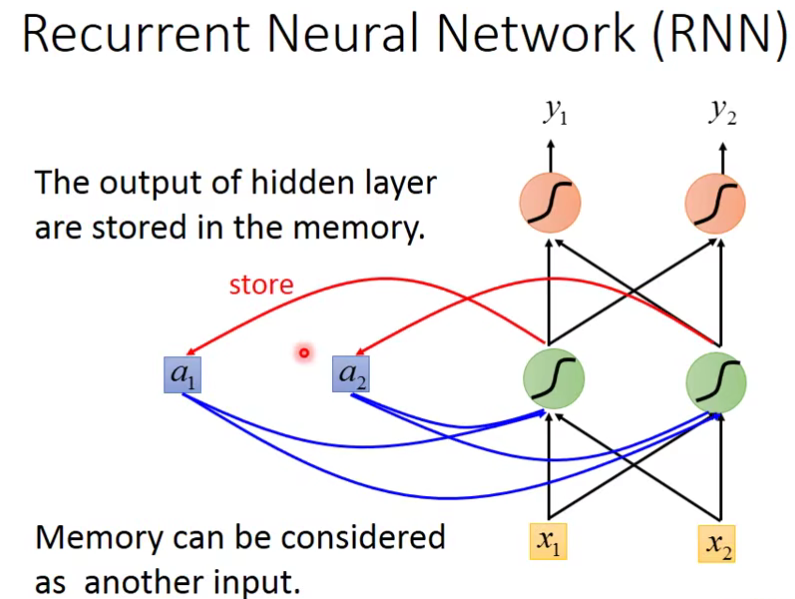
- 输入 x1,x2后,神经元的输出结果会存储到内存中
- 此时再输入 x1, x2 ,神经元不仅会此时的x1 ,x2,还会考虑之前 x1,x2的结果,综合后才得到输出。
例子: 点击查看更多
举个例子:为了计算方便,假设weight都是1,没有bias,激活函数也是线性函数。
先给memory那边初始值,假设都设置为0第,一个输入[1,1]
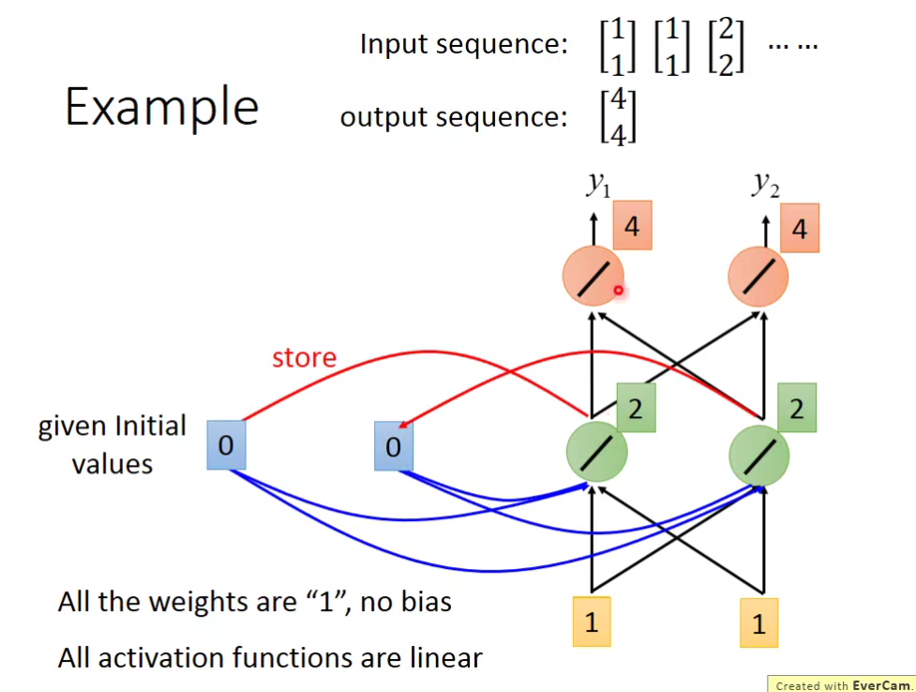
我们把绿色的[2,2]储存起来:
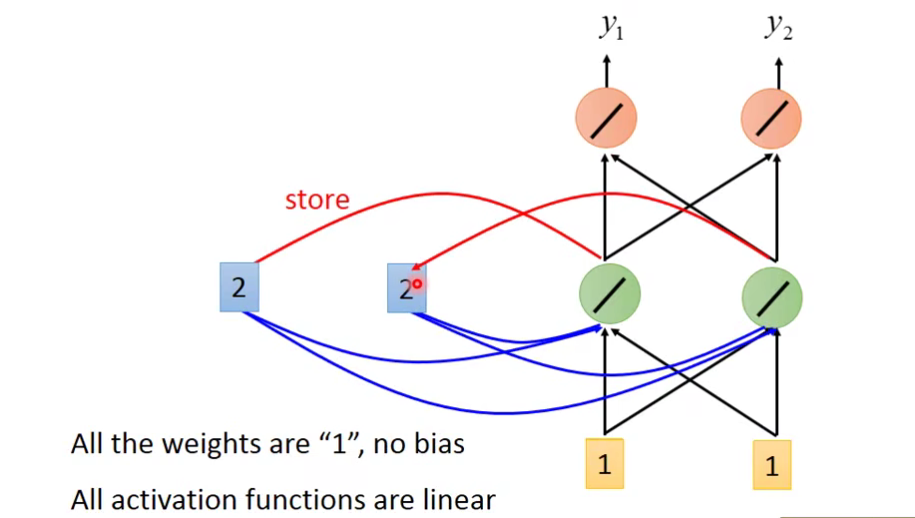
再第二个输入[1,1],把[6 ,6]储存起来。
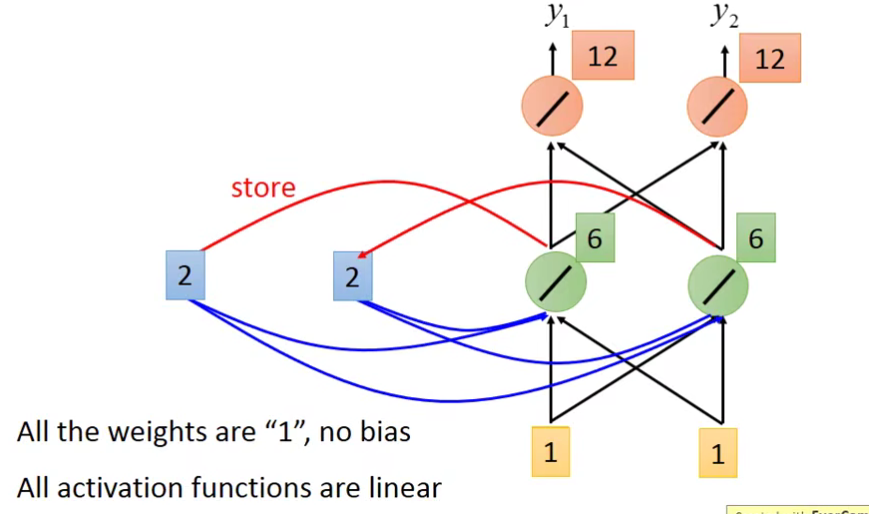
我们发现,在RNN里面就算输入是一样的东西,在这个network里面的output可能会是不一样的。
同样的操作一直进行。最后按照上面的输入结果是这样子的: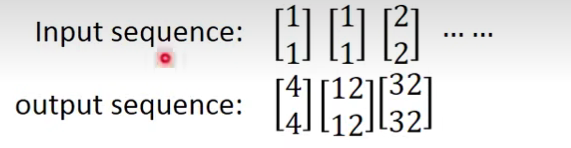
RNN特点:
- 输入是一样的东西,在这个network里面的output可能会是不一样的(存储的值可能不一样)。
- 改变输入的顺序,输出结果可能会不一样。
现在我们回到一开始的例子:
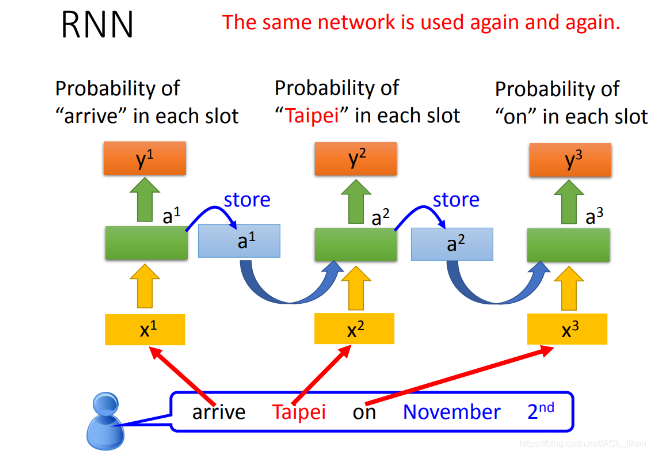
上图不是指有三个network,而是一个network被用了3次。同一个weight用同一个颜色表示的。
所以我们上面说的,输入同一个词汇,输出不同的结果的事情可以被解决。
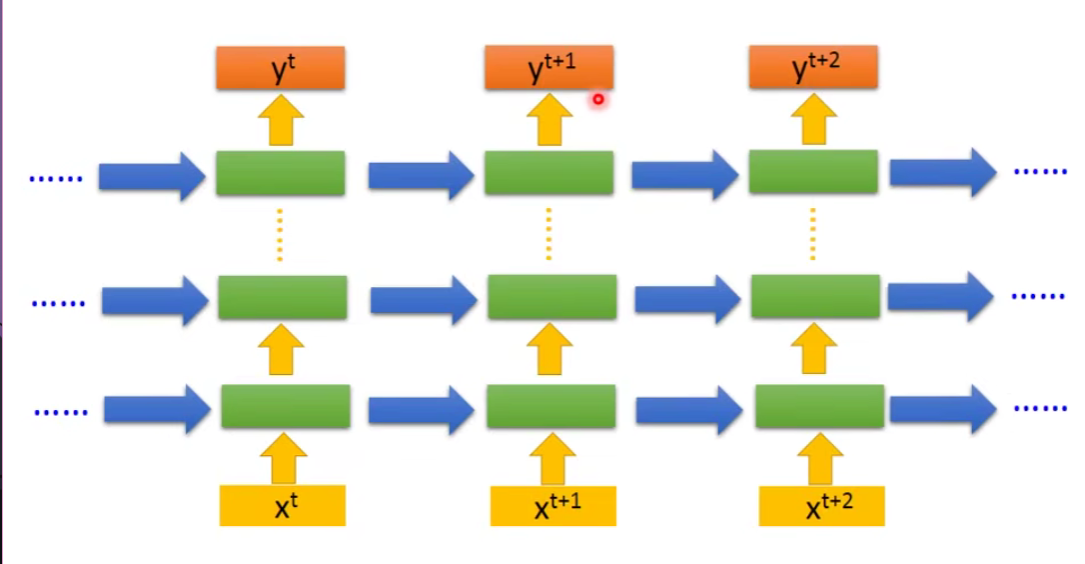
看我们上面的例子只有一个hidden layer,但是其实像设置几层都是可以的。
Of course it can be deep…
2. Elman Network & Jordan Network
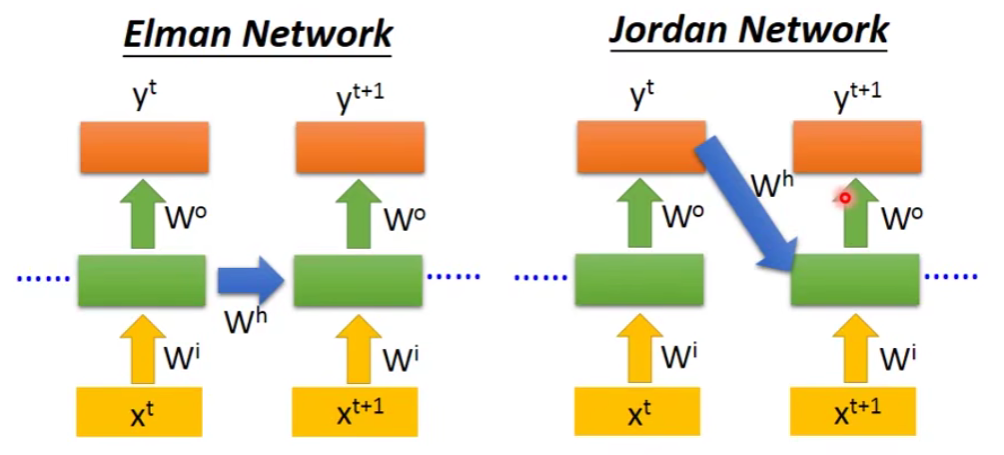
- Elman Network:(就是刚才举例的RNN)把某一个hidden layer的output存起来,在下一次使用network的时候,这个hidden layer会考虑现在的input和之前存的值,综合后再得出output。
- Jordan Network:它是把output的值存起来,下次用到再读出来。传说它的性能会好点,因为它存的是output的值,这个值和target比较有关系,所以此时我们知道存在memory的值大概会是怎样的。
3. Bidirectional RNN
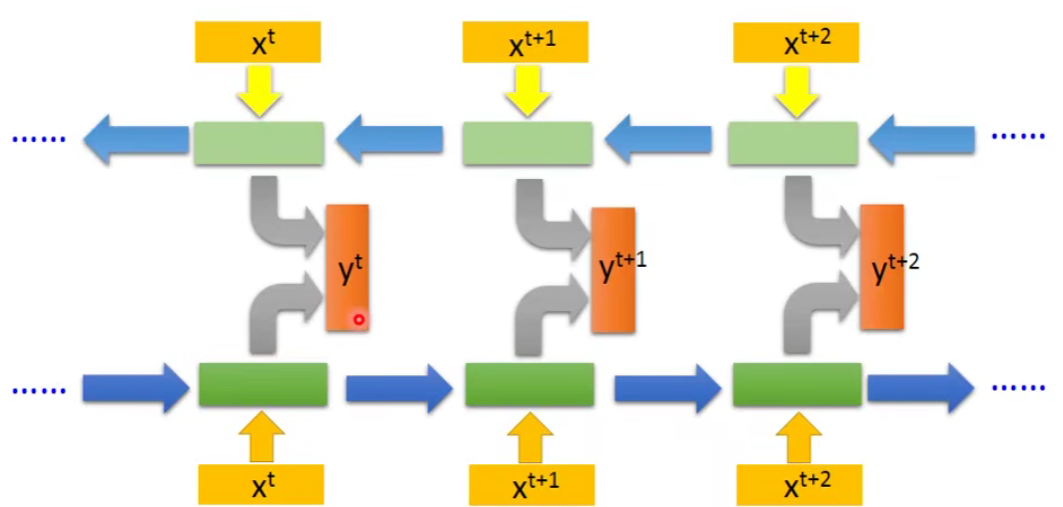
Bidirectional RNN的好处:network产生output的时候,它考虑的范围比较广。比如输入句子中间的词语进去,之前RNN只考虑了这个词语前面句子的部分。而Bidirectional RNN是考虑了句子前面和句子后面的部分,所以它的准确率会更高。
4. Long Short-term Memory(LSTM)
4.1 LSTM原理
我们上面讲的memory是最simple的版本,现在来讲我们常用的版本LSTM。
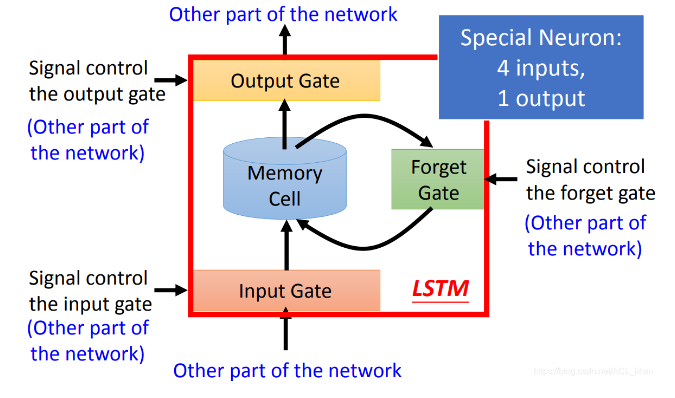
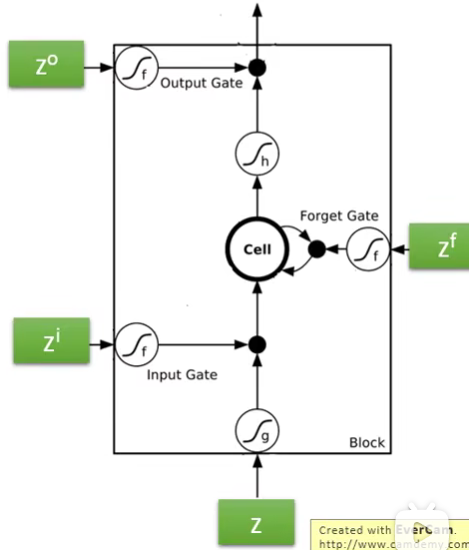
- Memory Cell:保存神经元的output
- Input Gate:决定神经元的output要不要被保存到Memory Cell(由network自己学习并决定是否打开阀门)
- Output Gate:决定神经元能不能从Memory Cell读取之前保存的东西(由network自己学习并决定是否打开阀门)
- Forget Gate:决定Memory Cell里面的东西要不要删掉(由network自己学习并自己决定是否Forget)
Special Neuron:4 input and 1 output
4 inputs:
- input的值
- 操控Input Gate的信号
- 操控Output Gate的信号
- 操控Forget Gate的信号
1 output: output是LSTM的输出值
LSTM是四输入一输出,其中有三个gate,每个gate打开还是关闭,都是学出来的。
接下来看看LSTM在具体公式中如何体现。
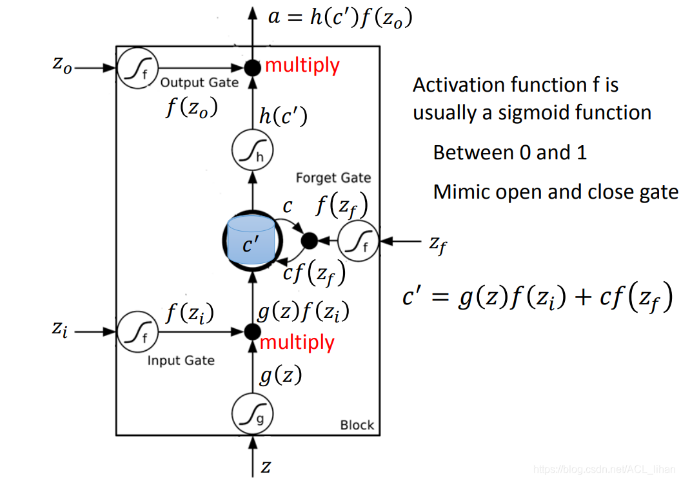
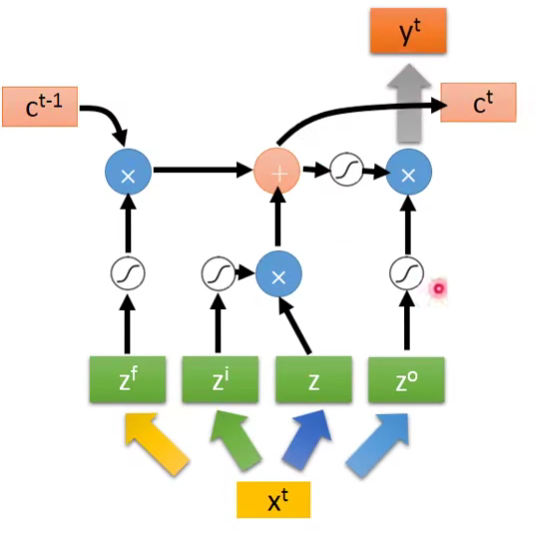
C表示Memory中存储的原始值,C’表示新的存储值。
可以看到,一个output受到三个gate的影响,首先是input gate决定一个input是否可以进入memory cell,forget gate决定是否要忘记之前的memory,而output gate决定最后是否可以输出。这样一个非常复杂的neuron。
解释:
- 输入是 z,经过激活函数后变成 g(z) 。
代表 是否开启 Input Gate 的信号,经过激活函数后变成 。数值为1代表完全让数据输入。 代表 是否开启 Output Gate 的信号,经过激活函数后变成 。数值为1代表完全让数据输出。 代表 是否开启 Forget Gate 的信号,经过激活函数后变成 。数值为0代表完全忘掉数据。
假设memory初始值是
从
是控制 输入的一个关卡,因为如果说 ,那么 就和没有输入一样。如果 为1,代表输入值 g(z) 能输入进memory。 - 如果
为1,代表保留memory原来的值 c ,并和输入的 g(z) 加起来,综合得到memory里新的值 c’ 。
4.2 LSTM - Example
那么实作上这个neuron是如何工作的呢?假设我们现在有一个最简单的LSTM,每个gate的input都是一样的vector,那么我们这边在做的时候就是每一个input乘以每个gate的matrix,然后通过active function进行计算。
下图演示了一个LSTM的基本过程,x1、x2、x3是输入序列,y是输出序列,基本原则是:
- 当时x2=1,将x1的值写入memory
- 当时x2=-1,将memory里的值清零
- 当时x3=1,将memory里的值输出
- 蓝色格子代表memory里的值。
- 红色格子代表输出的值。
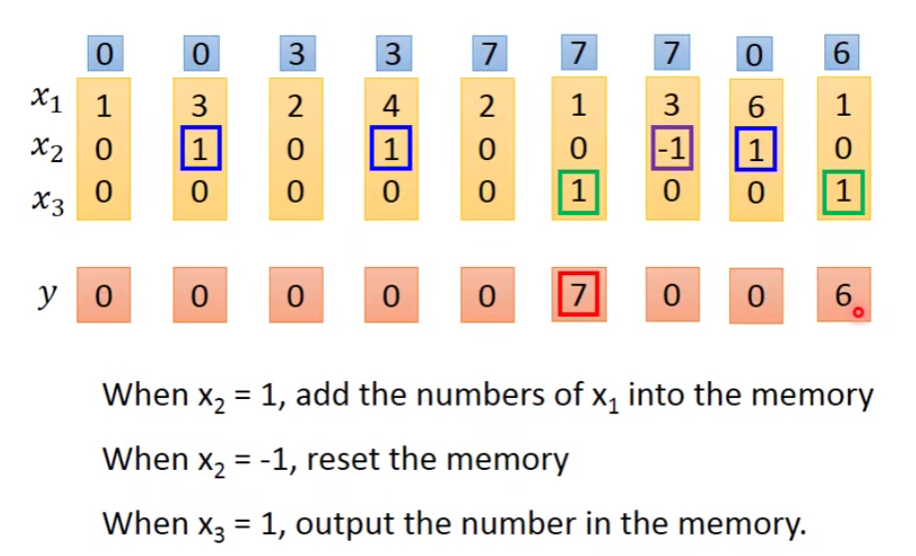
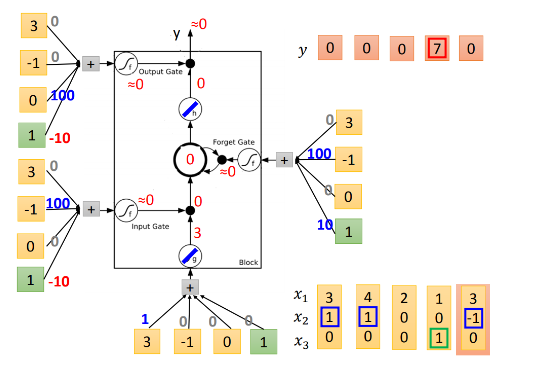
大致的规则就是这样,让我们代入LSTM中训练:
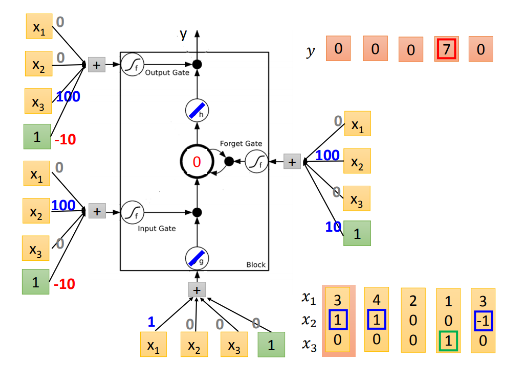
现在我们放第一个元素[3,1,0]进来。先看input =
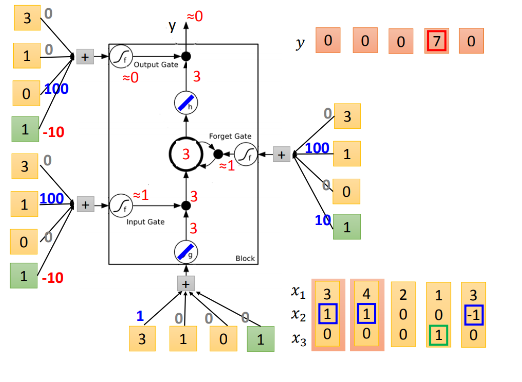
输入下一个元素[4,1,0]。先看input =
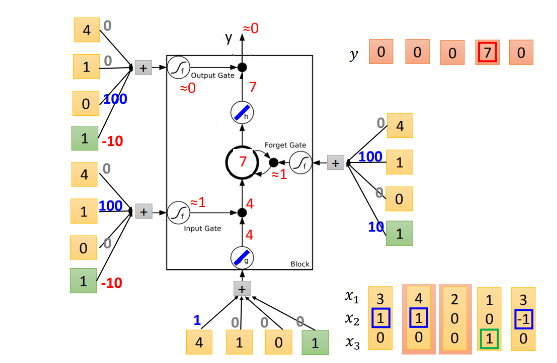
第三个元素类似的计算,发现input gate关闭,所以没法进入memory cell,因此memory cell没有更新。同时output gate关闭,没有输出。
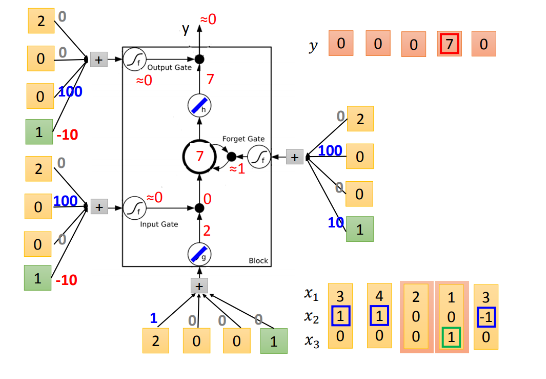
第四个元素进入,input gate关闭,memory cell不更新,但是这时候output gate的activate function得到1,所以开放输出结果。因为之前memory cell里面存放的是7,所以输出7。但是要注意一点,虽然memory cell的值输出了,里面的值并没有被清空,仍然保留着,所以这个时候的memory cell还是7。
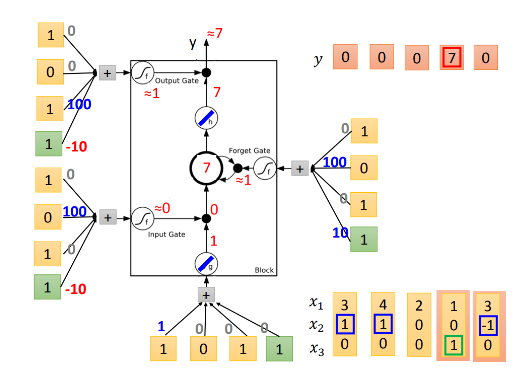
最后一个元素进入,input gate关闭,memory cell不更新,这时候,forget gate的activate function得到的是0,所以我们清空记忆,memory cell里面现在是0。output gate仍然关闭,所以没有output。
4.3 LSTM框架
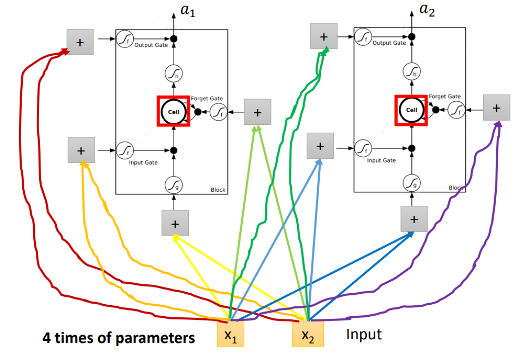
在原来的network里面,一个neuron就只有一个input和一个output。而在LSTM里面需要4个input产生一个output。所以LSTM需要的参数量会是一般的neural network的4倍。
那么这个和我们的RNN有什么关系呢,这样子看好像看不出什么来🤣
输入Xt先经过线性转化为4个vector组成的Z
比如第一个
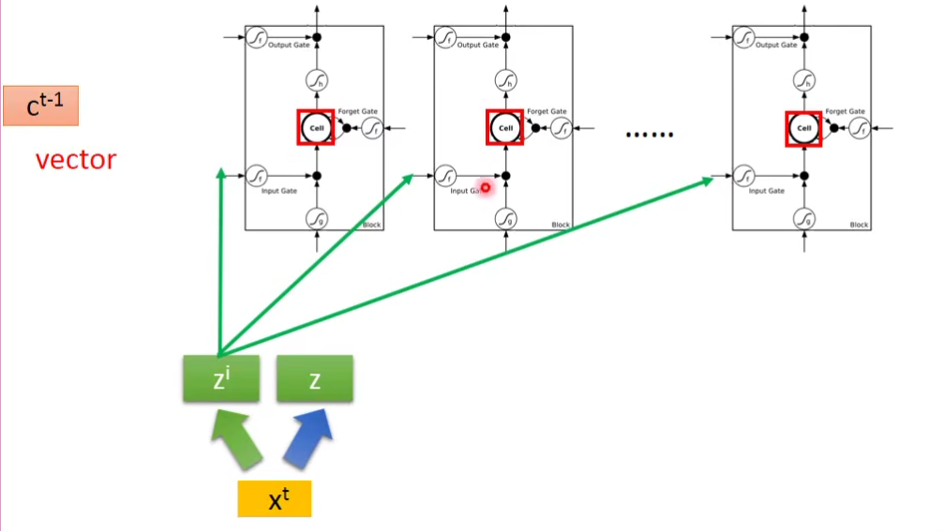
其他三个
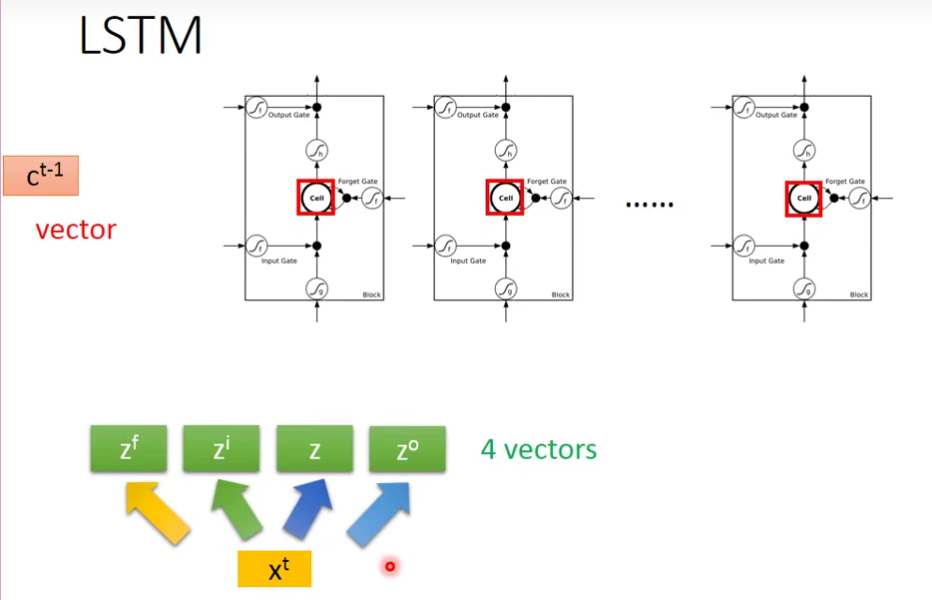
这4个
LSTM框架
- simple version
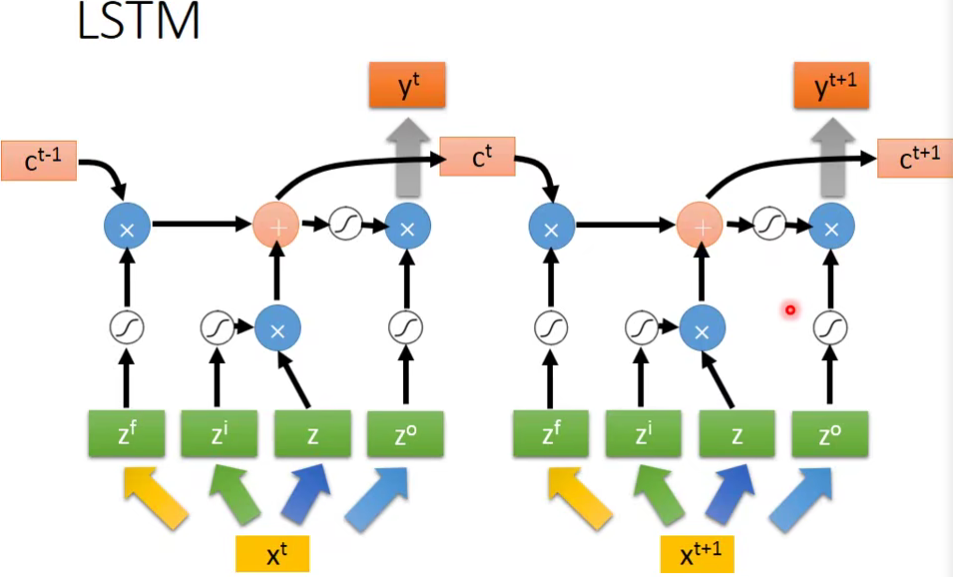
- hard version
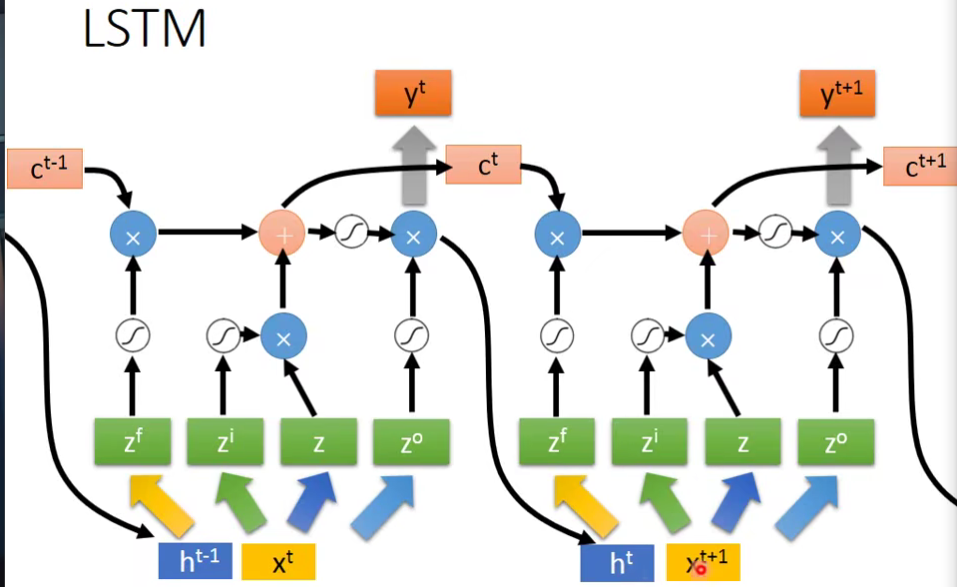
- 下一个事件点操控这些gate的值不仅是这个时间点的input,还看前一个时间点的output h
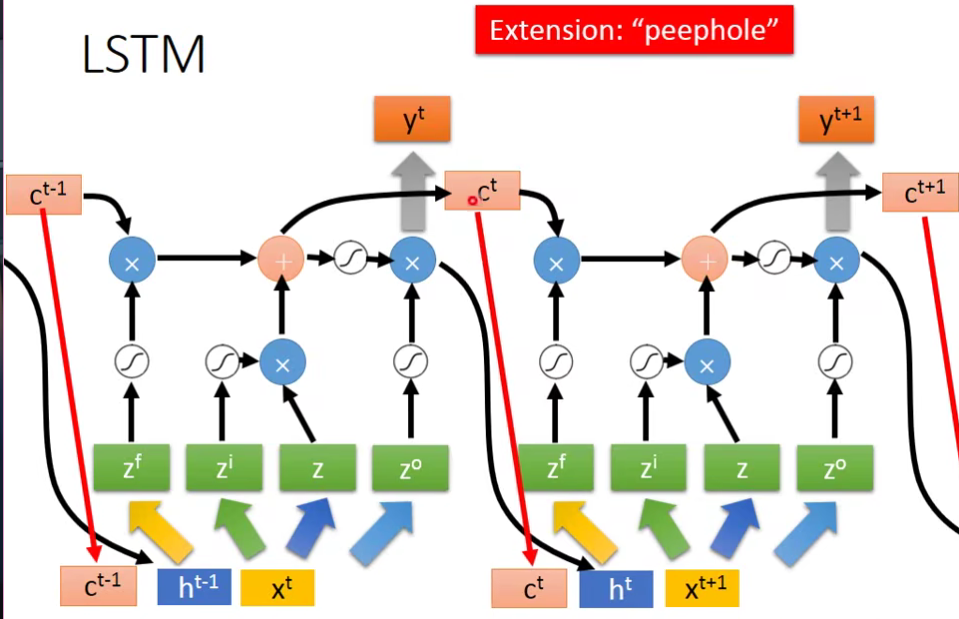
2.其实还不止上面那样,还加入了一个东西,叫做peephole。下一个事件点操控这些gate的值不仅是这个时间点的input,还看前一个时间点的output h和 上一个时间点存在memory cell里面的值。
当然一般我们不会只用一层啦,我们可以多叠几层
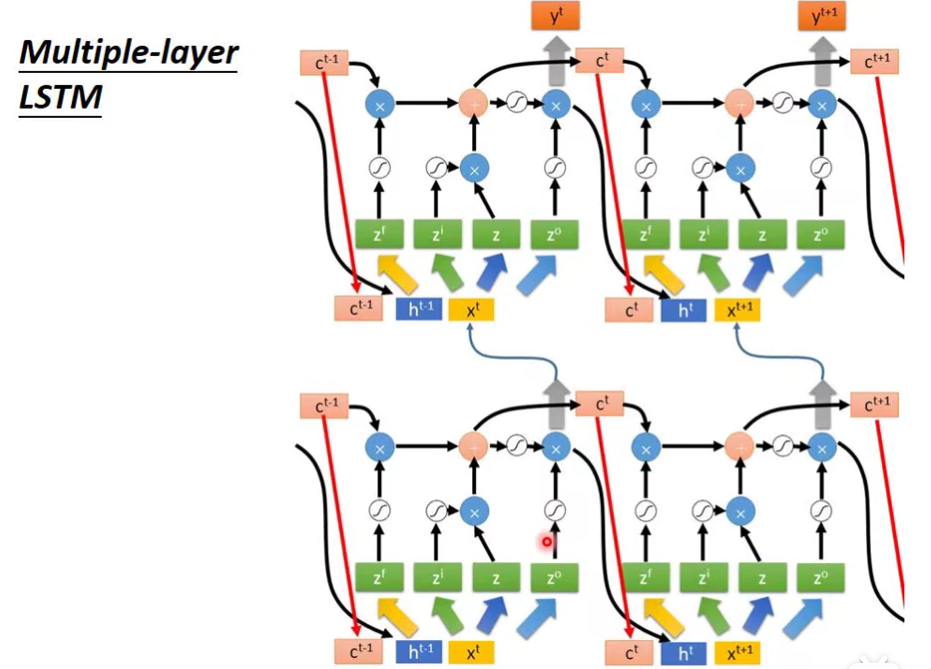
感觉嗯..很复杂对吧。但是这是现在LSTM的标准做法。
Don’t worry if you cannot understand this. Keras can handle it.
Keras supports “LSTM”,”GPU”,”SimpleRNN” layers.
- Title: 【从零开始的机器学习之旅】07-Recurrent Neural Network(RNN) PartⅠ
- Author: Nannan
- Created at : 2024-07-02 22:25:00
- Updated at : 2024-09-29 23:21:22
- Link: https://redefine.ohevan.com/2024/07/02/07-Recurrent Neural Network(RNN) partⅠ/
- License: This work is licensed under CC BY-NC-SA 4.0.