【从零开始的机器学习之旅】07-Recurrent Neural Network(RNN) PartⅡ
从零开始的机器学习之旅
1.Train RNN
在第一部分,我们已经知道RNN的大概样子了,接下来让我们来看看他的如何训练的吧
想要训练模型就要:
- 定义一个loss function
- 更新参数使loss function最小。
先来看第一个:定义一个loss function
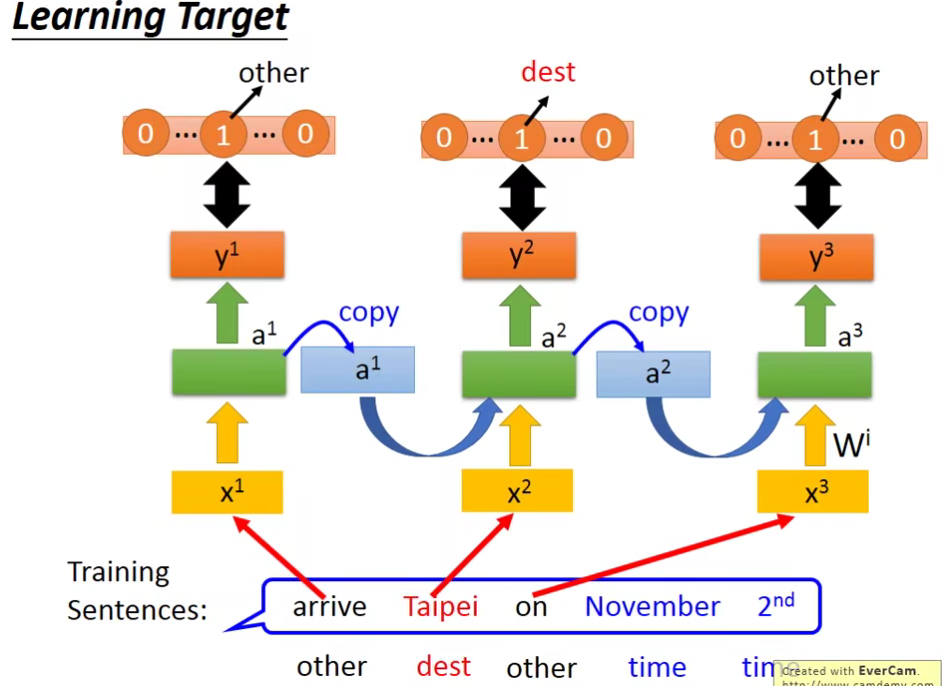
- 如果输入Taipei(Taipei是属于destination这个slot)。(这边输入的顺序和句子的顺序是一样的)
- 输入后,得到network的输出。这个输出是一个vector,这个vector的长度和slot的数目是一样的。如果network觉得Taipei是属于dest这个slot,则在dest这一维就会为1。
- 得到output后,再和target算cross entropy 。
这样就得到一个loss function。
接下来看第二个:更新参数使loss function最小。
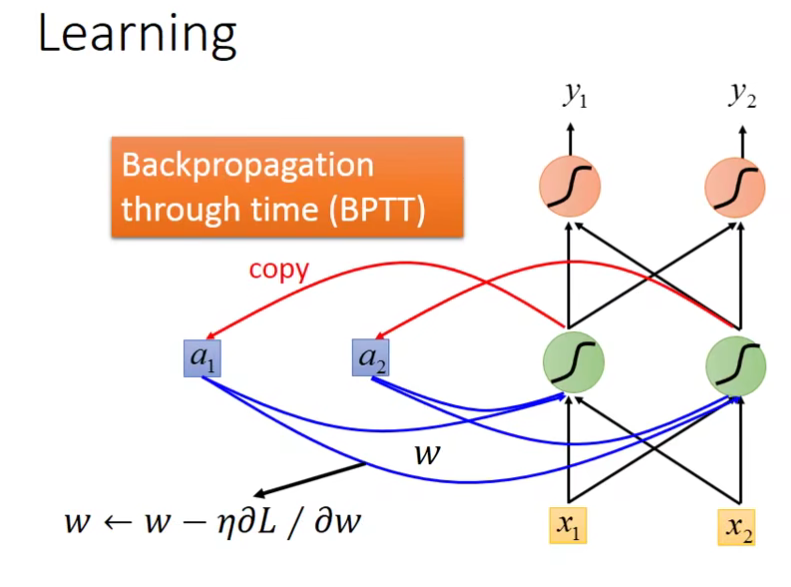
这边还是使用gradient descent来更新参数。之前为了让gradient descent更有效率的进行,有使用了反向传播(Backpropagation) 。不过这里需要考虑一个句子的顺序,所以需要改用Backpropagation的进阶版,Backpropagation through time (BPTT)。
2.Problem
Unfortunately…
- RNN-based network is not always easy to learn
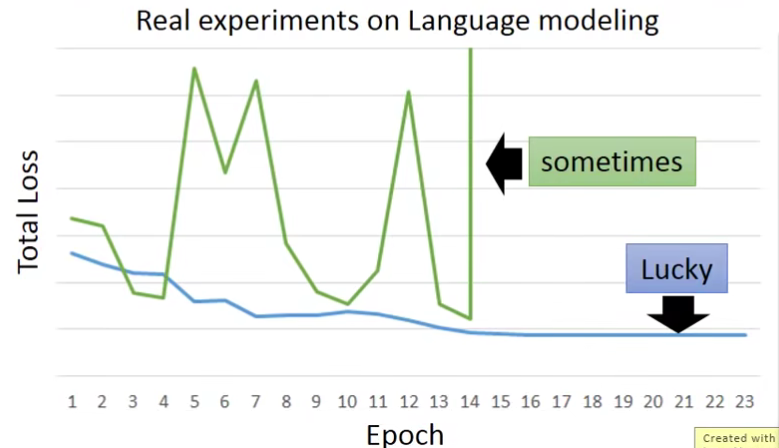
虽然上面有了loss function,也有了做gradient的方法。但是RNN没那么容易train。上图绿线就是实际train RNN的loss值,可以看到很不稳定。
这是因为RNN 的error surface是很崎岖的。
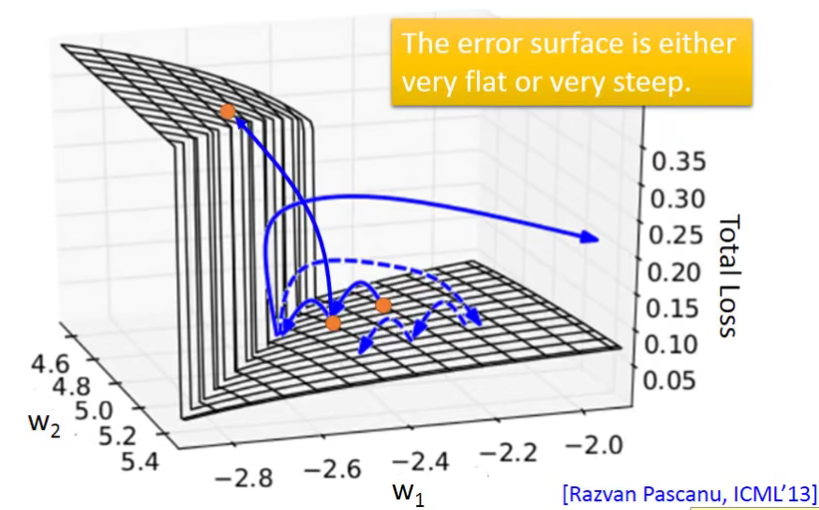
这会造成什么问题呢?
在平坦的surface上,由于gradient比较小,我们用比较大的learning rate。但是,一旦突然到了一个悬崖,这个时候的gradient突然增大,而我们的learning rate还没来得及变小。此时的loss会突然暴增。这就是为什么我们看见loss在图中这么的震荡。
还有更糟糕的情况,直接踩在了悬崖上,此时参数就会直接跑飞了(NAN),就像上面图中绿线直接顶上去了。
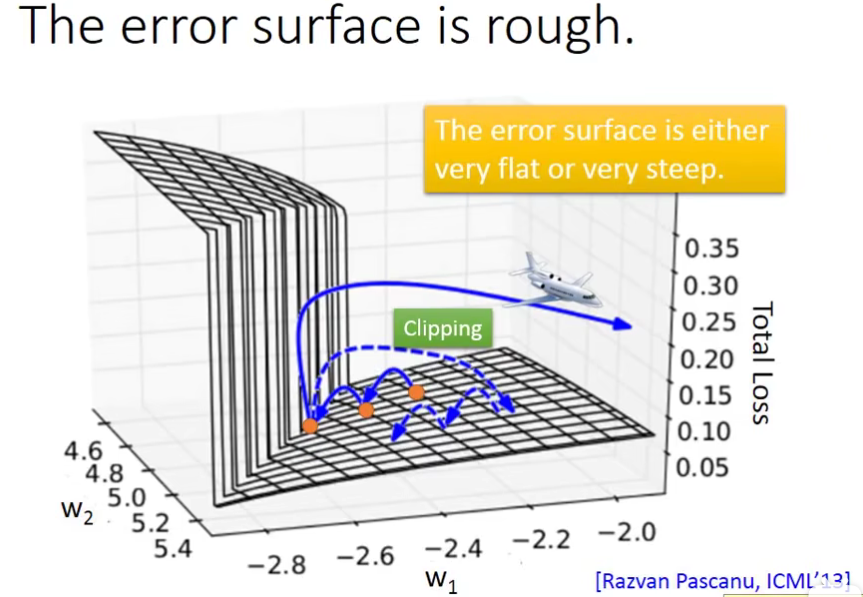
2.2 Solution —— 梯度裁剪(Gradient Clipping)
这个有什么解决办法吗?Clipping
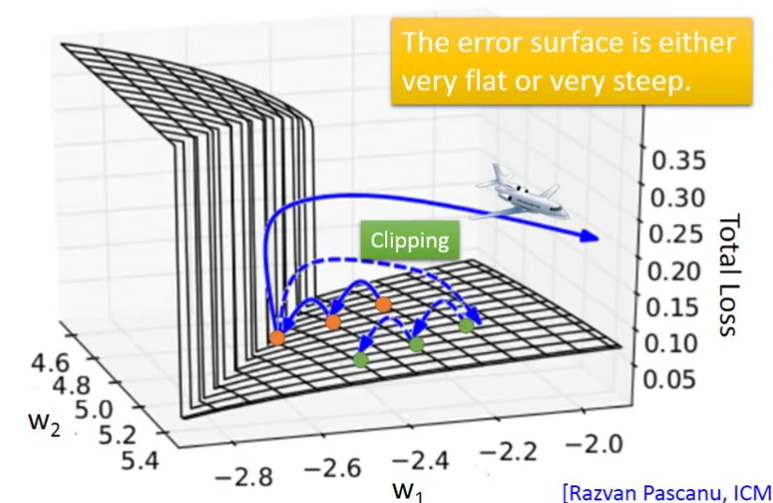
梯度裁剪(Gradient Clipping)是一种在训练神经网络时常用的技术,它用于防止梯度爆炸问题。梯度爆炸是指在训练过程中,梯度的大小急剧增加,导致权重更新过大,从而使得模型无法收敛或者性能急剧下降的现象。它人为地限制了梯度的大小。
使用梯度裁剪时应该注意以下几点:
- 裁剪阈值是一个超参数,需要根据具体任务进行调整。
- 梯度裁剪常用于训练RNN(递归神经网络)和LSTM(长短期记忆网络),因为这些模型特别容易出现梯度爆炸问题。
- 梯度裁剪可能会影响学习过程,因为它人为地限制了梯度的大小,这可能会防止模型探索参数空间的某些部分。
2.3 Why error surface steep?
为什么RNN 的error surface会这么崎岖?
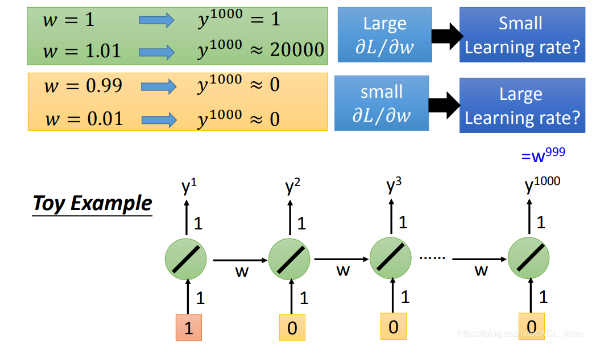
以上图的network为例子。上面一排network是代表不同时间点使用的,不是指有这么多个network。
这个network很简单。
- 只有一个神经元。这个神经元的output也会作为下一次神经元的input,加上下一时间点的input,一起被输入到下一时间点的神经元中。
- 所有weight都是1
现在input是[1,……,0],除了第一个是1,其他都是0 。
那么时间点为1000的output就是
在这整个过程中,神经元的那个weight被使用了999次。所以,w的变化有两种影响:
要么就是1变成1.01,造成gradient的巨大变化
要么就是0.99变成0,但是gradient约等于没变化
由于这里有两种变化情况,所以不能很死板地说,用大的learning rate或者小的learning rate就是好的。
所以RNN不好train的原因是:它有时间顺序,同样的weight在不同的时间点会被反复使用多次。
2.3.1 Helpful Techniques
解决办法其实就是LSTM啦。
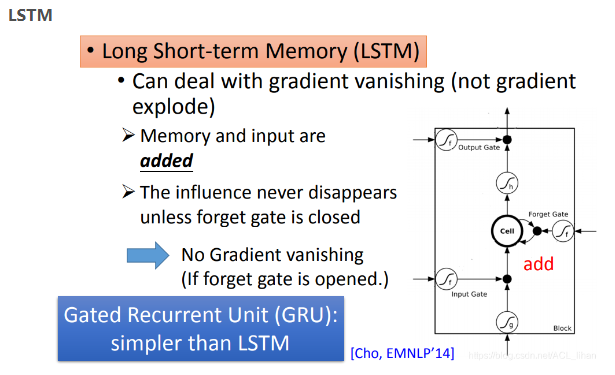
使用LSTM可以解决gradient vanishing的问题(即error surface平坦那部分的问题),原因:
- 原始的RNN中,后一个时间点输入到memory cell的值会直接覆盖前一个时间点memory cell的值,这相当于把前一时间点的w对memory cell的影响给消除掉了,所以会容易产生gradient vanishing的问题。
- 而LSTM中,如果forget gate打开(即保留memory cell的值),memory cell值会是上一个时间点的memory cell的值加上现在 input的值。所以原来的 w 对 memory cell 造成的影响还保留着,没有被直接消除掉。所以训练的时候,可以给一个bias,使得forget gate在大多数时候都被开启。
另外,如果使用LSTM发生过拟合(由于LSTM有3个gate,参数比较多)。可以改用一个比LSTM简单的版本 ,Gated Recurrent Unit (GRU),它只有2个gate(它把input gate和forget gate联动起来):
- 当input gate被打开,forget gate就会被自动关闭(即清除原来memory cell的值)。
- Title: 【从零开始的机器学习之旅】07-Recurrent Neural Network(RNN) PartⅡ
- Author: Nannan
- Created at : 2024-07-03 22:25:00
- Updated at : 2024-09-29 23:21:27
- Link: https://redefine.ohevan.com/2024/07/03/07-Recurrent Neural Network(RNN) partⅡ/
- License: This work is licensed under CC BY-NC-SA 4.0.