《PyTorch深度学习实践》04.Dataset and DataLoader
《PyTorch深度学习实践》
1.Mini-Batch
我们之前在做训练用的是自己的数据集,我们每次做前馈的时候都是把整个数据集丢进去。
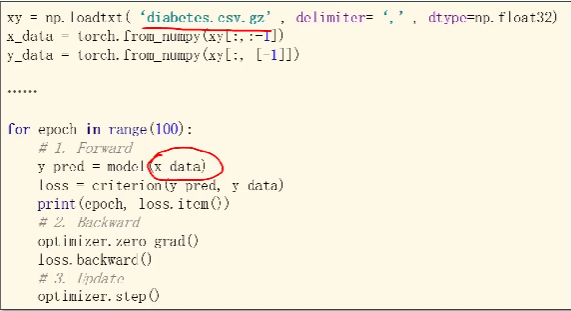
我们在进行梯度下降的时候,我们有两种选择:
- 全部的样本(Batch)都用——可以最大化利用向量计算的优势来提高计算的速度。
- 只用一个样本(随机梯度下降)——有比较好的随机性,可以帮助我们跨越以后可能遇到的鞍点。性能会好,但是用时长(一个样本没法利用gpu并行能力)
为了综合以上两个的优点,我们在深度学习的时候会利用Mini-Batch

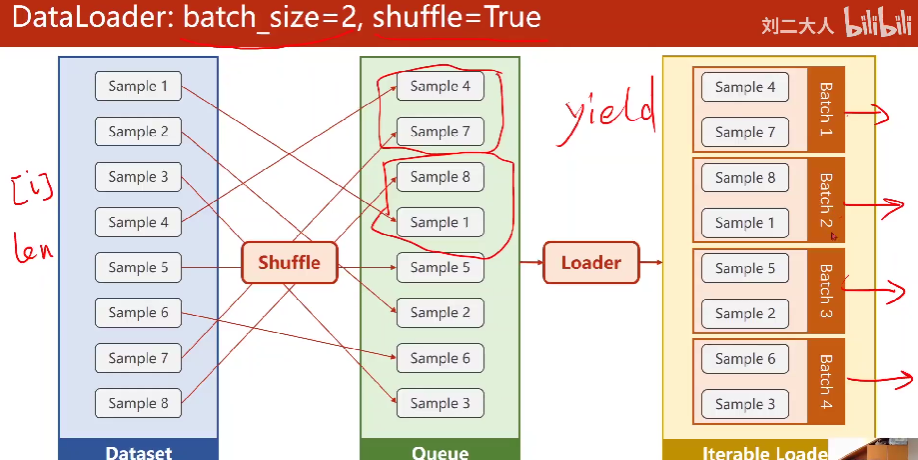
2. DataLoader
重要的参数:
- batch_size
- shuffle : 为了提高训练的随机性,我们可以选择对数据集进行打乱。
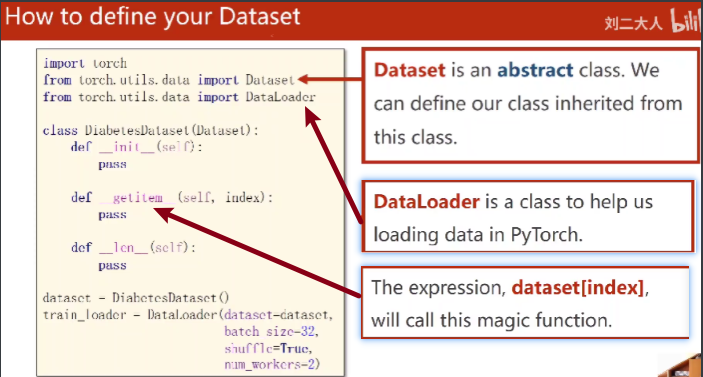
那么我们的数据集需要支持索引,使得DataLoader能访问到里面的每一个元素,还需要知道这个dataset的长度。
code:
Extra: num_workers in Windows
在windows下运行可能会遇到一些问题,比如以下这个代码,会出现RE的问题:

解决方法:把用loader进行迭代的代码封装一下,也就是上图的for语句封装一下,不要直接暴露在程序里面就行了。

下面来实现一下数据集类:
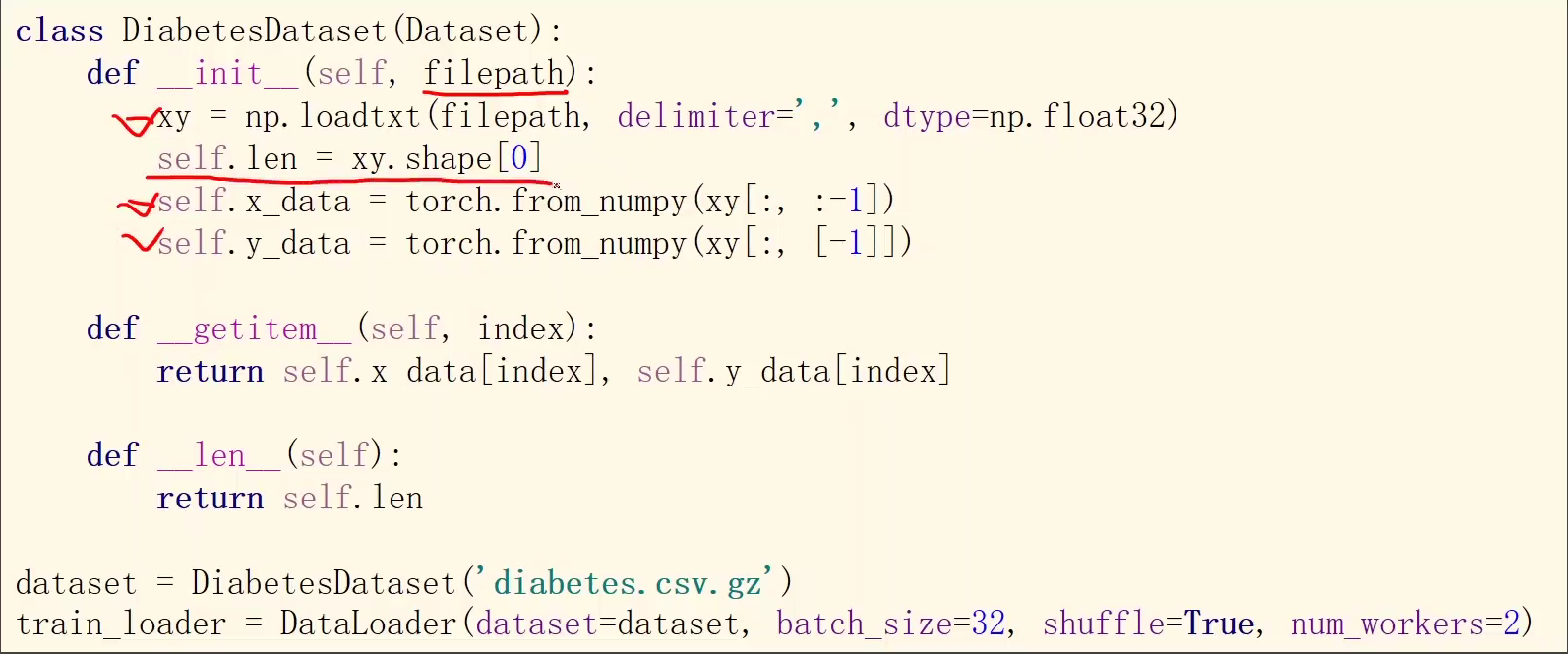
Using DataLoader

Classifiying Diabetes
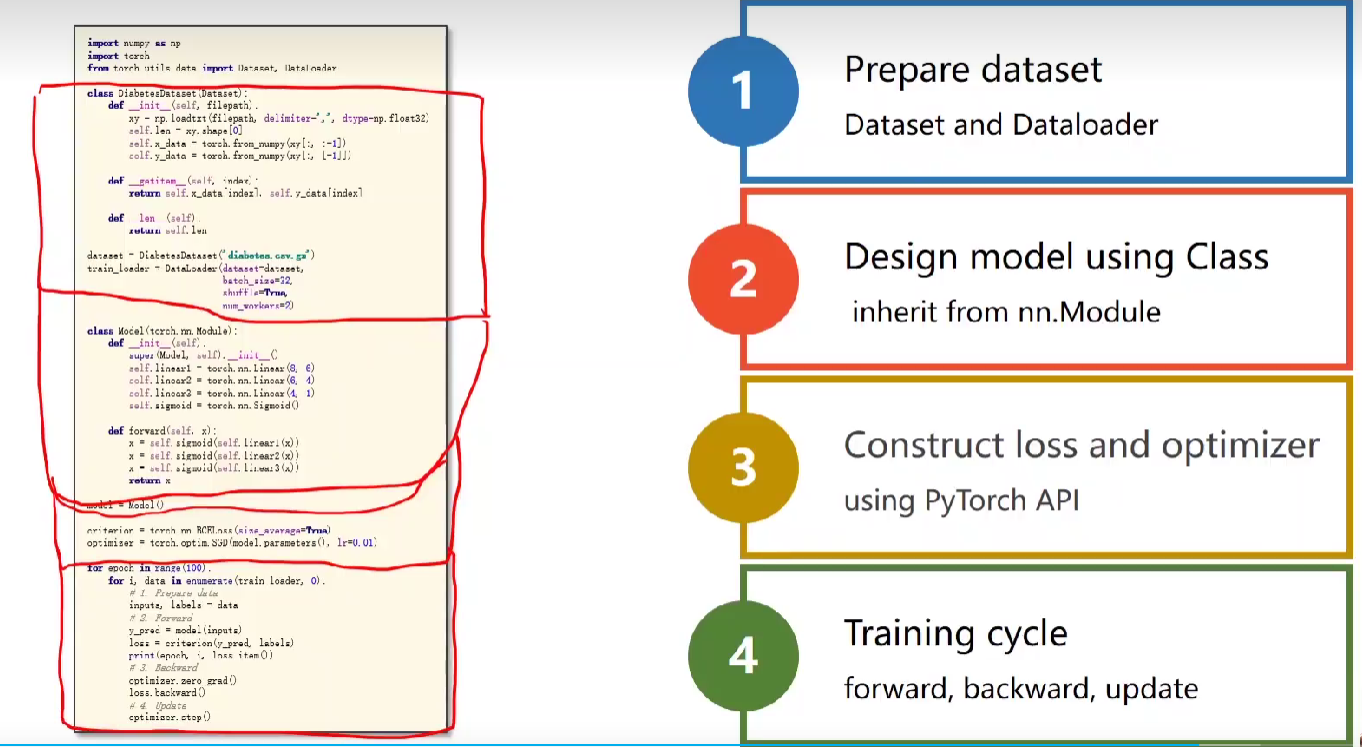
3.Code
1 | import numpy as np |
- Title: 《PyTorch深度学习实践》04.Dataset and DataLoader
- Author: Nannan
- Created at : 2024-07-13 21:52:41
- Updated at : 2024-09-29 23:20:36
- Link: https://redefine.ohevan.com/2024/07/13/【实践】04.Dataset and DataLoader/
- License: This work is licensed under CC BY-NC-SA 4.0.
Comments